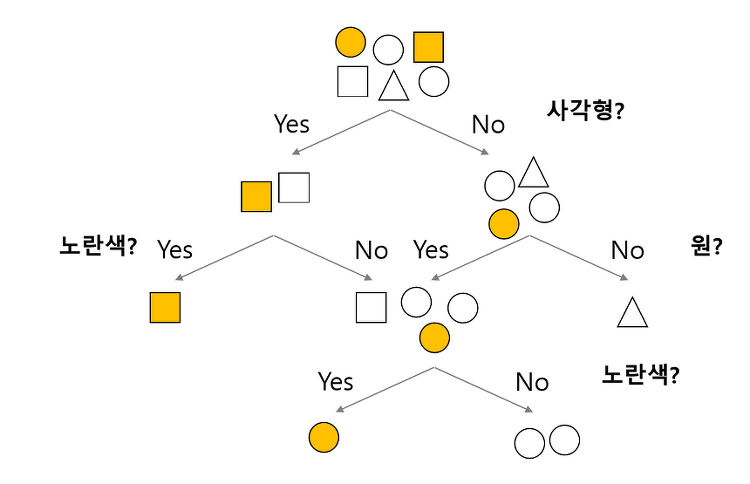
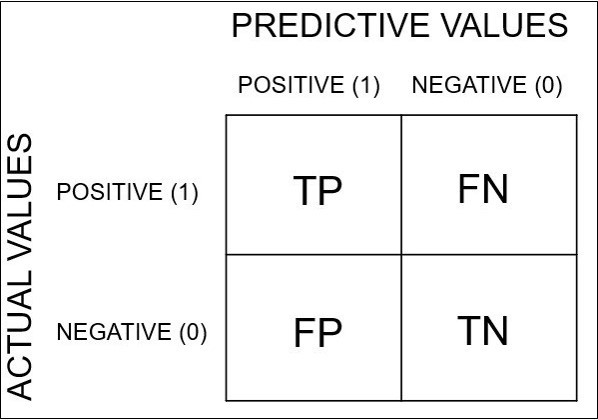
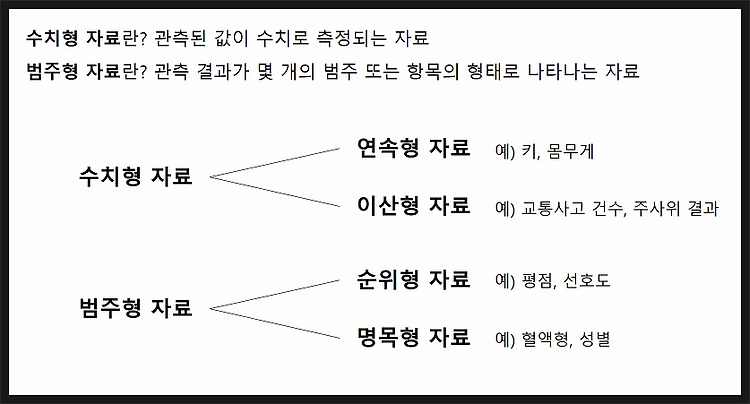
의사결정나무란? Decision Tree란? 의사결정 규칙을 나무구조로 나타내에 전체 데이터를 소집단으로 분류하거나 예측하는 분석기법 전체 데이터에서 마치 스무고개하듯이 질문하며 분류해나간다. 그 모양이 마치 나무와 같아서 의사결정 나무라 부른다. 예) 나무에서 분할되는 부분을 노드(node) 라 하고, 가장 처음 노드를 root node, 가장 마지막 노드들을 terminal node라 한다. 그렇다면, 위의 예시에서 모양 or 색 중에서 무엇을 먼저, 어떤 기준으로 나눠야 할까? 그 답은 불순도가 낮아지는 방향으로 나눠야 하며, 그 방법으로 ID3, CART, C4.5 등 여러 알고리즘이 있다. 본 포스팅에서는 ID3에 대해 알아보고자 한다. ID3 알고리즘에 대해 알아보기에 앞서, 불순도란 무엇이며..