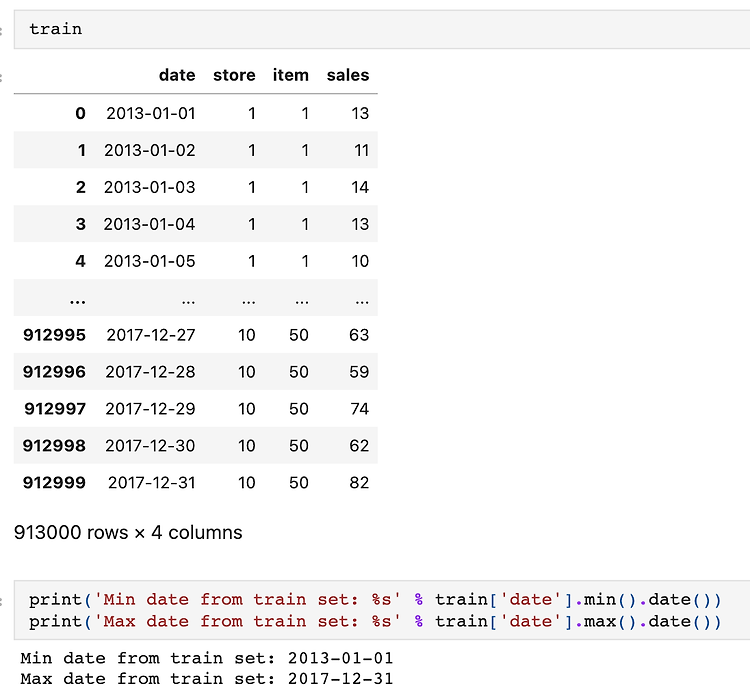
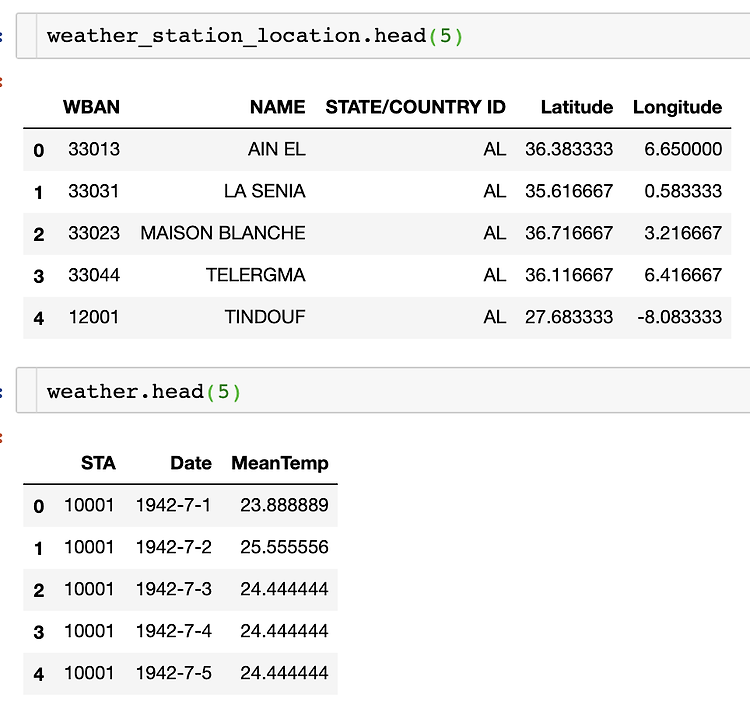
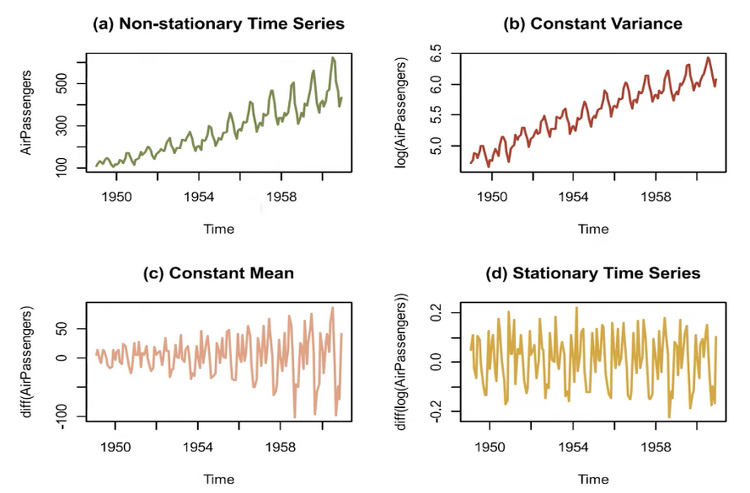
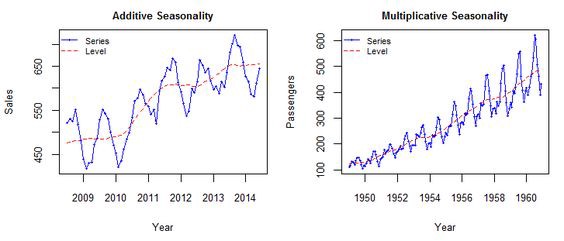
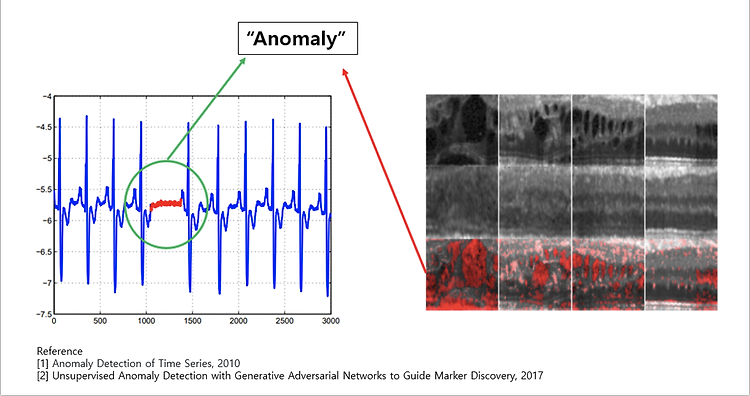
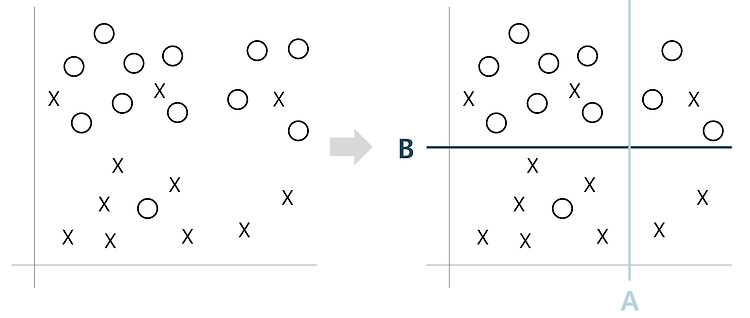
2020년 4월에 ICLR 개재된 RaPP를 Tensorflow로 구현해보았다. 논문 링크 : https://openreview.net/forum?id=HkgeGeBYDB RaPP: Novelty Detection with Reconstruction along Projection Pathway A new methodology for novelty detection by utilizing hidden space activation values obtained from a deep autoencoder. openreview.net 참고 링크 : https://makinarocks.github.io/rapp/ RaPP - Novelty Detection with Reconstruction along Proje..