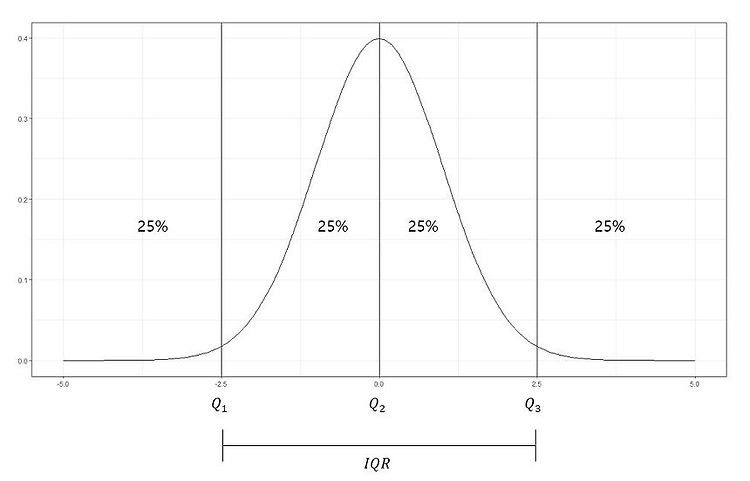
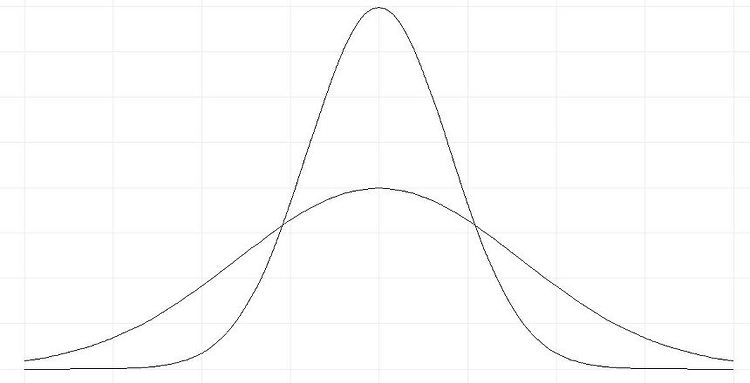
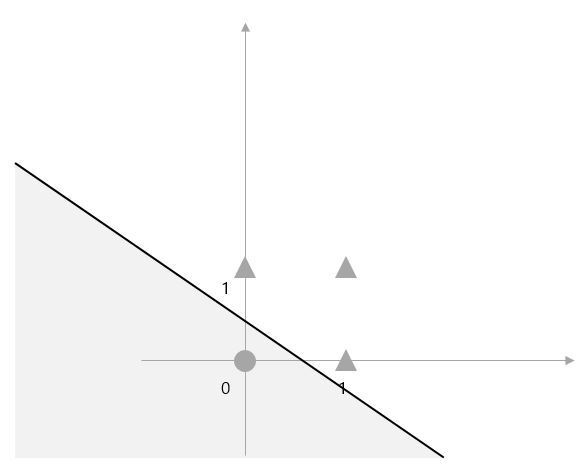
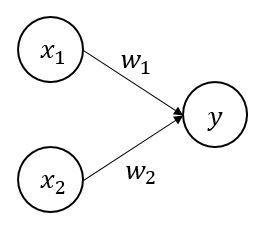
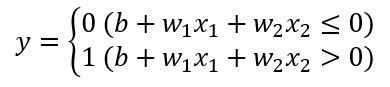지난 포스팅들에서 자료를 표현하는 방법에 대해 알아보았다. >> 평균 vs 중앙값 vs 최빈값 바로가기 >> 분산과 표준편차란? 바로가기 특히 지난 시간에는 퍼진 정도를 나타내는 분산과 표준편차에 대해 알아보았다. 이번에는 백분위수와 사분위수에 대해 알아보겠다. 백분위수란? What is Percentile? 중앙값은 전체의 관측값을 반으로 나누는 경계값이다. 즉, 중앙값은 전체의 관측값 중 50% 위치에 해당하는 값이다. 이 개념을 확장하여 전체 관측값을 크기 순서대로 배열했을 때, 전체의 관측값을 (100xp)%와 100x(1-p)%로 나눌 수 있는 값을 백분위수라 한다. 자료의 수가 n개 일때, 제 100 x p 백분위수는 그 값보다 작거나 같은 관측값의 개수가 np개 이상이고, 그 값보다 크거나 ..