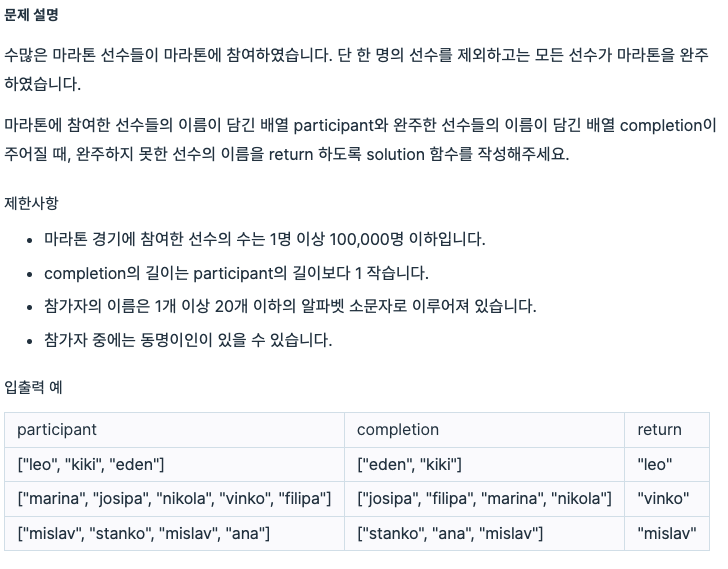
(Python 코딩테스트 연습) Programmers 완주하지 못한 선수 파이썬으로 풀어보기 https://programmers.co.kr/learn/courses/30/lessons/42576?language=python3# 코딩테스트 연습 - 완주하지 못한 선수 수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다. 마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수 programmers.co.kr Solution from collections import Counter def solution(participant, completion): result = list(set(participant)-set(complet..