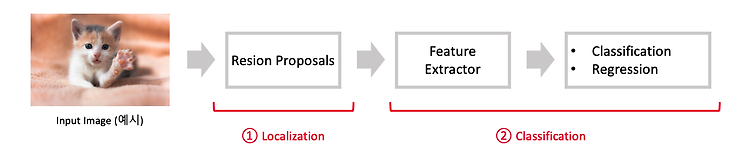
지난시간에 Object Detection 이란 무엇인지 간단히 알아보고, 주요 용어들에 대해 알아보았다. 2022.03.31 - [AI/Object Detection] - Object Detection이란? Object Detection 용어정리 Object Detection이란? Object Detection 용어정리 Object Detection이란? Object Detection은 말 그대로 물체를 검출하는 문제이다. 딥러닝으로 이미지 관련 무언가를 한다면 대체로 다음과 같다. 1. Classification 가장 기본이 되는 문제이다. 이미지가 주어 leedakyeong.tistory.com 이번에는 Object Detection을 하기 위한 딥러닝 알고리즘들 중 2-Stage 방식과 1-Stag..