지난시간에 Object Detection 이란 무엇인지 간단히 알아보고, 주요 용어들에 대해 알아보았다.
2022.03.31 - [AI/Object Detection] - Object Detection이란? Object Detection 용어정리
Object Detection이란? Object Detection 용어정리
Object Detection이란? Object Detection은 말 그대로 물체를 검출하는 문제이다. 딥러닝으로 이미지 관련 무언가를 한다면 대체로 다음과 같다. 1. Classification 가장 기본이 되는 문제이다. 이미지가 주어
leedakyeong.tistory.com
이번에는 Object Detection을 하기 위한 딥러닝 알고리즘들 중 2-Stage 방식과 1-Stage 방식에 대해 알아보고,
1-Stage 방식 중 YOLO v1에 대해 자세히 알아보겠다.
YOLO를 설명하기에 앞 서, Object Detection의 여러 알고리즘에 대해 알아보겠다.
Object Detection은 크게 2-Stage 방식과 1-Stage 방식이 있다.
2-Stage 방식은 다음과 같이 물체의 ① 위치를 찾는 문제(Localization)와 ② 이미지가 무엇인지 분류(Classification) 문제를 순차적으로 해결한다.

즉, Image가 주어졌을 때,
① 물체가 있을 법한 위치들을 찾은 후
② 각각의 위치에 대해 Feature를 추출하여 이것을 토대로 Class를 분류한다.
또, 위치 정보를 정확히 조정하는 Regression 단계도 Classification과 함께 거친다. (Bounding Box 좌표 예측)
2-Stage 방식의 대표적인 알고리즘은 R-CNN 계열이다.
R-CNN, Fast R-CNN, Faster R-CNN 등이 여기에 속한다.
반면, 1-Stage 방식은 다음과 같이 Localization문제와 Classification 문제를 한 번에 해결한다.
일반적으로 2-Stage 방식보다 속도는 빠르지만 정확도는 낮다는 특징이 있으며, 대표적인 알고리즘으로는 YOLO 계열이 있다.
하지만 최근 나온 YOLO v4, v5의 경우 정확도도 많이 개선되어 실시간성으로 Object Detection을 해야하는 경우에는 대부분 YOLO를 사용한다.
참고로 Object Detection 알고리즘들의 History는 다음과 같다.
2-Stage인 R-CNN이 2013년에 먼저 나왔고, Faster R-CNN 이후 1-Stage 방식인 YOLO가 2016년에 나왔다.
외에도 2020년 4월에 YOLO v4가 나왔고, 같은 해 6월에 YOLO v5가 나왔다.
YOLO Label
YOLO의 작동 원리를 설명하기에 앞 서, 각 이미지에 대해 Ground Truth Label이 어떻게 되어있는지 먼저 설명하겠다.
PASCAL VOC 이미지를 내려받아보면, 각 이미지에 대해 다음과 같이 Annotaion이 있다.
이 데이터는 여기서 다운받을 수 있다.
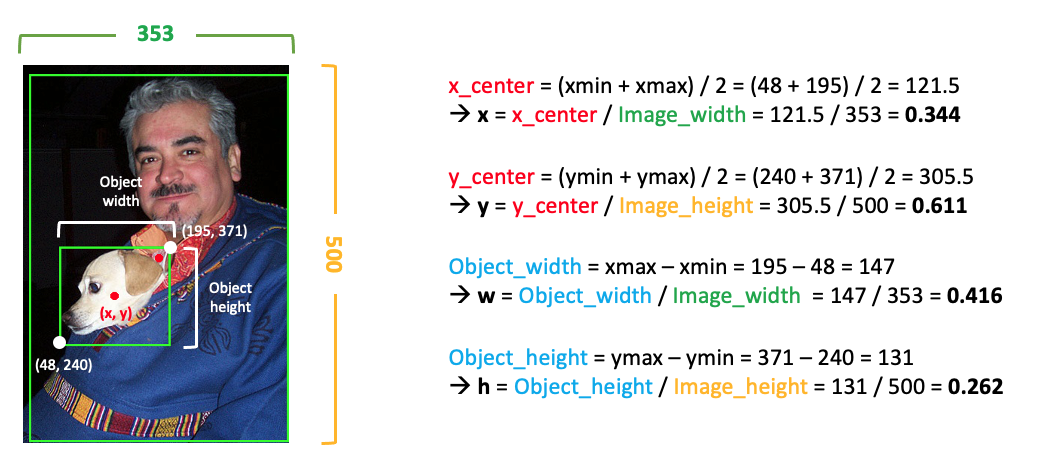
Annotation은 Image 전체 Size(width, height), 이미지에 포함된 각 Object 별 Class와 좌표(xmin, ymin, xmax, ymax)로 이루어져있다.
이를 YOLO에 맞는 Label로 바꾸어 주어야하는데, YOLO는 기본적으로 (x, y, w, h)의 좌표를 사용하고 여기서 x와 y는 Object의 center point, w와 h는 Object의 width와 height를 의미한다.
즉, Annotation을
x_center = (xmin + xmax) / 2
y_center = (ymin + ymax) / 2
object_width = xmax - xmin
object_height = ymax - ymin으로 바꿔주어야한다.
단, 모든 좌표는 0~1 값으로 normalization 시킨다.
즉,
x = x_center / Image_width
y = y_center / Image_height
w = object_width / Image_width
h = object_height / Image_height 로 바꾸어준다.
최종적으로 dog의 좌표는
x = ((48+195)/2)/353 = 0.344
y = ((240+371)/2)/500 = 0.611
w = (195-48)/353 = 0.416
h = (371-240)/500 = 0.262 가 된다.
dog라는 물체의 중심좌표 중 x는 전체의 왼쪽부터 34.4%에 위치하고, y는 위에서부터 61.1%에 위치하며,
width는 전체 중 41.6%를 차지하고, height는 전체의 26.2%를 차지한다고 해석할 수 있다.
이를 할 장의 이미지로 정리하면 다음과 같다.
이렇게 각 이미지별로 Annotation을 YOLO Lable에 맞게 이미 바꿔놓은 데이터는 여기서 다운받을 수 있다.
위 이미지에 대해 아래와 같이 이미 YOLO에 맞게 Labeling 되어있다.

11은 Dog을, 14는 Person으로 각 Class를 의미하고, 이후 4개 좌표가 x, y, w, h이다.
YOLO v1 : You Only Look Once
YOLO v1을 한 장의 이미지로 설명하면 다음과 같다.
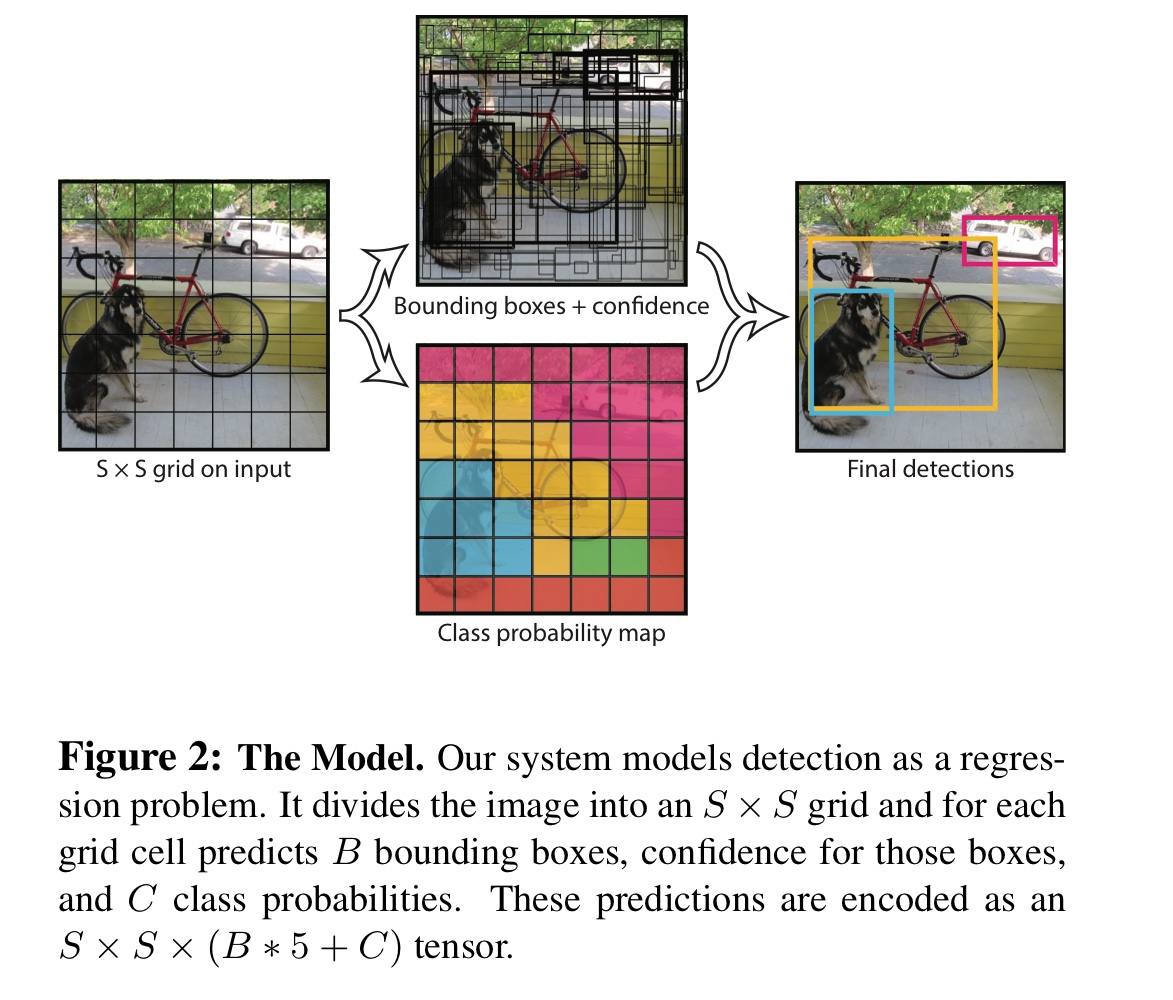
1. 먼저 Input Image가 들어오면 S x S의 Grid로 이미지를 나눠준다. (논문에서는 S를 7로 했다.)
(만약, 이미지의 Size가 700x700이면 하나의 Grid Cell은 100x100이 된다.)
2. 이후 각 Grid Cell에 대해 두 가지 Task를 동시에 진행한다.
① Bounding Box
② Classification
3. NMS를 거쳐 겹치는 Box들을 쳐내고 최종 결과만 보여준다.
2-①. 각각의 Grid Cell은 B개의 Bounding Box를 계산한다. (논문에서는 B를 2로 했다.)
각 Bounding Box는 Box의 중심 x, y좌표와 w, h 그리고 Confidence Score를 가진다.
즉, 이미지를 YOLO v1 모델에 넣었을 때, 나오는 Ouput Shape은 S * S * (B * 5)가된다.
Confidence Score는 박스가 물체를 포함하는지에 대한 확률값과, 예측한 박스가 얼마나 정확한가에 대한 정도를 반영한다.
즉, Confidence Score는 다음과 같이 정의된다.
confidence=Pr(Object)∗IoU(pred,true)
Pr(Object)는 해당 박스에 물체가 존재하면 1(Ground Truth의 Center Point가 포함되면), 존재하지 않으면 0이되는 확률값이고,
IoU(pred,true)는 Ground Truth와 Prediction box간의 IoU(Intersection over Union)값을 의미한다.
단, 여기서 x와 y는 각 Grid Cell에 정규화된 Center point이고, w와 h는 역시 Grid Cell에 정규화된 Width와 Height이다.
즉, Ground Truth는 이미지 전체에 대해 어디에 위치하고 얼마나 차지하는지였다면,
각 Grid Cell에 대해 어디에 위치하고 얼마나 차지하는지를 의미한다.
Coodination
위 YOLO Label에서 사용한 이미지를 7 x 7로 Grid를 나누고, 각 Object에 대해 Bounding Box(초록색 box)와 Center Point(빨간색 점)을 표시하면 다음과 같다.

center point는 강아지의 경우 7 x 7 Grid Cell에서(5,3)위치에 있고, 사람의 경우 (4,4) 위치에 있다.
따라서 위 이미지에 대한 Label 중 Confidence Score는 7 x 7에서 나머지는 다 0이고 (5,3)과 (4,4)위치에만 1이 있어야 한다.

다음으로 x, y, w, h는 dog object의 x좌표로 설명하겠다.
다음은 dog object의 center 좌표가 포함된 grid cell을 확대한 모습이다.
이 grid cell이 마치 전체 이미지이고, 그 때의 center point를 정규화한다고 생각하면 된다.
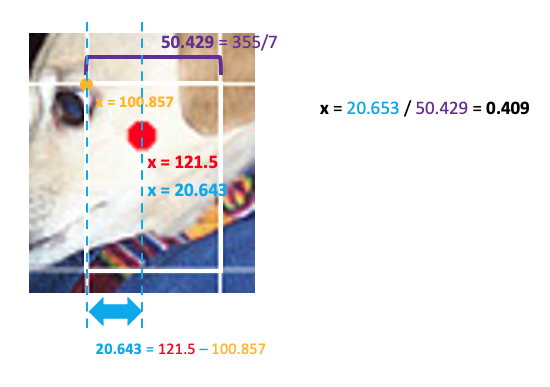
dog의 원래 x좌표는 121.5이고, Grid Cell의 width는 50.429(Image_width / S = 355 / 7)이다.
dog의 x좌표는 7x7 Grid Cell에서 왼쪽부터 세 번째 칸에 위치해 있으므로 dog의 x좌표를 포함하는 Grid Cell의 왼쪽 x좌표는 100.857(=50.429 * 2)이다.
그러므로 해당 Grid Cell에 대한 새로운 x좌표는 20.643(=121.5 - 100.857)이 된다.
이를 다시 0~1로 정규화해주면 최종적으로 x좌표는 0.409(=20.653 / 50.429)가 된다.
즉, dog의 center 좌표는 세 번째 Grid Cell에서 왼쪽부터 40.9%에 위치한다고 해석할 수 있다.
단, x와 y는 기존과 같이 0~1의 값을 가지나, w와 h는 1보다 큰 값을 가질 수 있다.
x와 y는 각 Grid Cell에서 어디에 위치해 있는지에 대한 값이라면, w와 h는 Grid Cell의 w와 h 대비 몇배에 해당하는지를 의미한다.
즉, 위 이미지에서 Grid Cell의 width는 50.429였고, 실제 dog의 bounding box의 width는 147이었으므로
w = 147 / 50.429 = 2.915가 된다.
최종적으로 [0.34419263456090654, 0.611, 0.4164305949008499, 0.262]이었던 dog는
(5, 3) Grid Cell에 대해 [0.40934837, 0.277, 2.9150143, 1.834]가 되고,
[0.509915014164306, 0.51, 0.9745042492917847, 0.972]이었던 person은
(4, 4) Grid Cell에 대해 [0.56940496, 0.56999993, 6.8215294, 6.804]가 된다.
2-②. 동시에 각각의 Grid Cell에 대해 Classification을 수행한다.
여기서 주의할 점은 각 Bounding Box에 대해서가 아니라 각 Grid Cell에 대해서이다.
Bounding Box에 상관없이 Grid Cell 별로 C개의 Class에 대해 class probablities Pr(classi|object)를 예측한다.(논문에서는 PASCAL VOC 데이터를 사용하여 총 class 개수는 20개로, C는 20이다.)
이 때의 shape은 S x S x C가 된다.
Pr(classi|object)는 object에 대한 조건부 확률로, object가 있을 때만 계산하고 object가 없을 때는 계산하지 않는다.
C개의 Class에 대해 모든 확률값이 계산되고, 그 중 가장 값이 높은 Class가 해당 Grid Cell의 Class가 된다.
2-①과 ②는 동시에 실행되므로 모델의 최종 output shape은 S x S x (B * 5 + C) = 7 x 7 x 30 이 된다.
(S = 7, B = 2, C = 20)
최종적으로 NMS를 거쳐 겹치는 Bounding Box들 중 Confidence Score가 높은 것들만 남기고 제거해주고, Class도 매핑해서 Return한다.
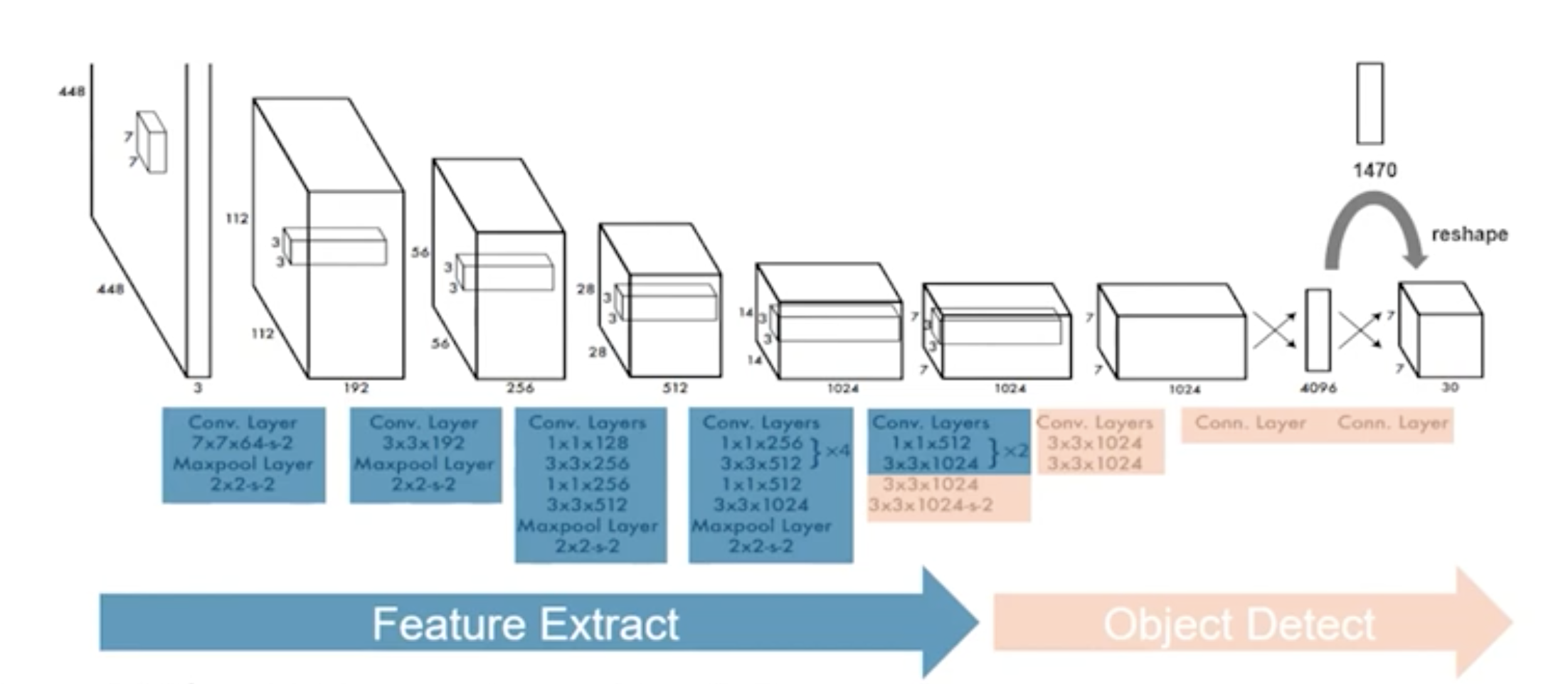
YOLO v1에서 사용한 Network Architecture는 다음과 같다.
마지막 layer의 shape이 7 x 7 x 30인 것을 확인할 수 있다.
OD를 수행하는 모델은 크게 두가지 구조로 이어져있다.
1 Backbone
2. Head
위 이미지에서 파란색 부분이 Backbone, 그 뒤가 Head이다.
Backbone은 입력받은 이미지에서 특징을 추출하는 역할을하고, Head는 특징이 추출된 feature map을 받아 Detection하는 역할을 한다.
Backbone은 특징을 추출하는 것이 주 목적이기 때문에 특징 추출에 최적화된 모델인 Classification 목적으로 만들어진 모델을 사용하고,
ImageNet 데이터로 pre-train된 모델을 그대로 가져와, OD에 fine tuning하여 사용한다.
YOLO v1이 만들어질 당시 가장 성능이 좋은 Classification 모델은 VGG었고, YOLO 저자들은 이를 변형한 DarkNet 모델을 사용한다.
* 참고로 DarkNet은 본 논문의 저자(Joseph Redmon)가 독자적으로 개발한 프레임워크로, DNN을 학습시킬 수 있는 툴이다. C언어로 작성된 오프소스로, 연산이 빠르고 설치가 쉬우며 CPU 및 GPU 연산을 지원한다는 특징이 있다.
Pre-train 할 때는 ImageNet dataset 그대로 224x224 사이즈로 학습하고, 실제 Inference할 때는 해상도를 위해 448x448 사이즈를 입력 데이터로 받는다.
마지막 layer인 7x7x30 에 대해 확대해서 살펴보면 다음과 같다.
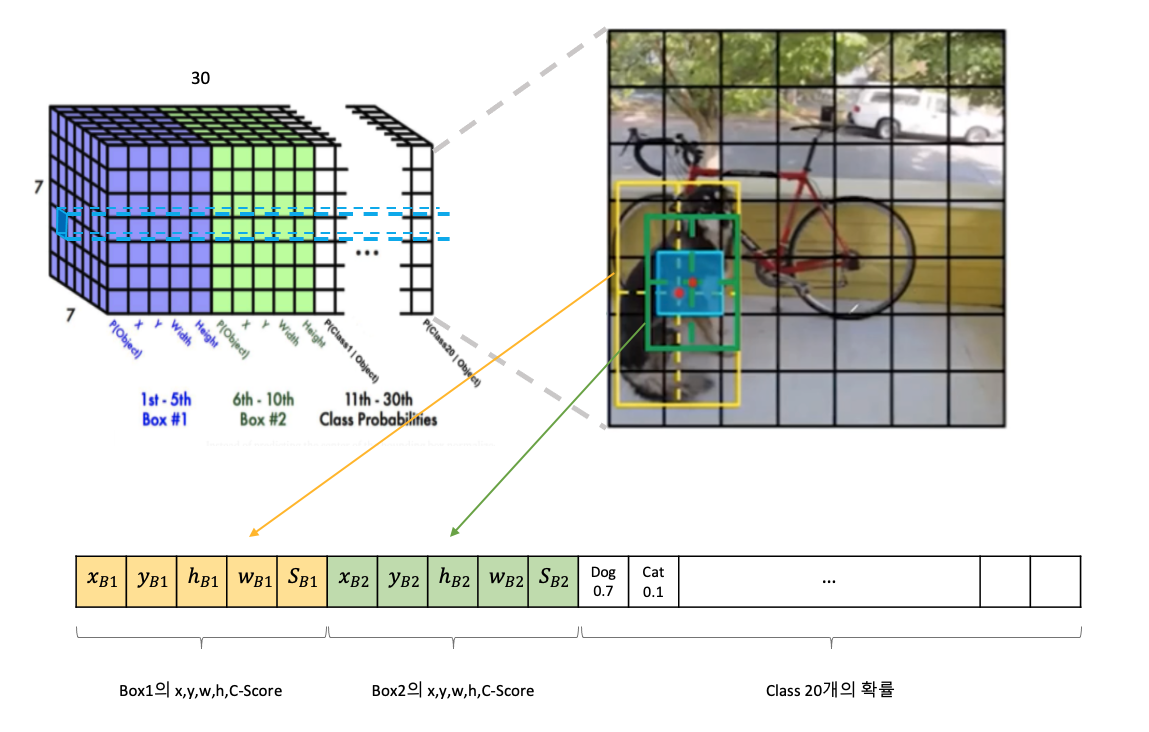
위에서부터 5번째, 왼쪽부터 2번째인 파란색 Grid Cell에 대해 예시로 살펴보면,
두 개의 Bounding Box가 나오고 각 Box에 대한 x, y, w, h와 Confidence Score가 계산된다.
그리고 20개의 Class에 대한 확률도 계산된다.
마지막으로 Loss는 다음과 같이 계산된다.

모든 Grid에 대해 Localization Loss, Confidence Loss, Classification Loss가 계산된다.
이 때, 모든 Box에 대해 Loss가 계산되지는 않고, Grid 별 두 개 Box 중 Ground Truth와 IoU가 더 큰 한 개 Box에 대해서만 Loss를 계산하고 학습한다.
λ는 모두 hyper parameter로 논문에서는
Localization loss를 Confidence loss에 비해 높은 가중치를 주기 위해 λcoord=5로,
객체가 존재하지 않는 배경이 되는 Grid Cell이 훨씬 많기때문에 끼치는 영향을 낮추기 위해 λnoobj=0.5로 정해주었다.
1objij는 if object가 존재한다면 과 같은 의미, 1noobjij는 if object가 존재하지 않는다면 과 같은 의미이다.
Localization loss의 경우 object가 존재하는 Box에 대해서만 네 좌표에 대한 regression loss를 계산하고,
Confidence loss는 object와 존재할 때와 존재하지 않을 때 모두 계산한다.
마지막으로 Classification loss는 object가 존재 할 때만 계산해서
세 loss를 모두 더해준다.
이 loss를 최소화시키도록 모델을 학습하면 끝이다.
여기서 주목할 점은 noobj이다.
2-Stage Object Detection 모델들은 background class를 따로두고 학습하지만, YOLO 계열은 Confidence Score가 일정 Threshold 이하이면 background라고 판단하면 되기 때문에 background class를 따로 두지 않는다.
* Loss를 모든 Grid Cell에 대해 수행한다는 것은, 기존의 Label을 모든 이미지에 대해 S*S*(B*5+C) 형태로 만들어줘야한다는 것을 의미한다.
마지막으로 Expreriments는 다음과 같다.
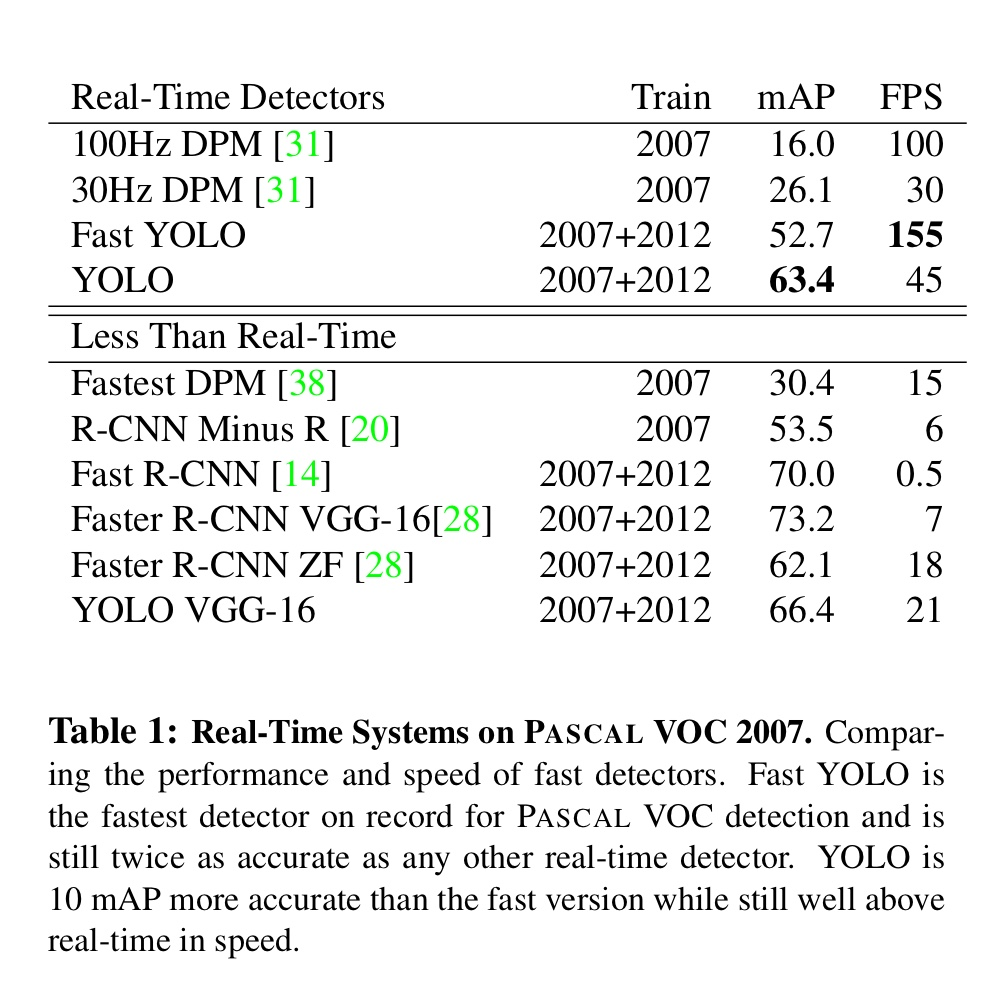
mAP는 63.4이며, 초당 45장의 이미지를 처리할 수 있다.
네트워크를 경량화하여 개발한 Fast YOLO의 경우 정확도는 조금 포기했지만 초당 155장의 이미지를 처리할 수 있다.
YOLO가 정확도가 가장 높은 모델은 아니지만, 실시간성으로 비디오에서 물체를 검출하는 문제를 풀 때 문제없을 속도를 내고있다.
YOLO v1은 1-stage 알고리즘으로, 빠른 속도를 자랑하지만 작은 물체에 대해서는 탐지가 잘 안된다는 단점이 있다.
그 이유는 Loss Function에서 두 Box 중 Ground Truth와 IoU가 큰 하나의 Box만 학습에 사용하는데,
큰 객체에 대해서는 Bounding Box간 IoU가 크게 차이나기 때문에 둘 중 더 적절한 후보군을 잘 선택할 수 있는 반면,
작은 객체에 대해서는 약간의 차이가 IoU의 결과값을 뒤집을 수 있기 때문이라고 진단했다.
이 문제는 YOLO v3에서 Feature Map의 크기를 13x13, 26x26, 52x52로, 세 가지 Scale에 대해 Prediction을 수행하면서 해결했다.
실제로 사람이 어떤 이미지에서 물체를 찾는다고 생각했을 때도 작은 이미지에서는 큰 물체를 발견하기 쉬울 것이고, 큰 이미지에서는 작은 물체를 발견하기 쉬울 것이다.
YOLO v3는 이 원리를 적용하여 작은 물체도 잘 Detect할 수 있는 알고리즘을 개발했다.
'AI > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLO v1 ~ v6 비교(1) (6) | 2022.06.23 |
|---|---|
| [Python] Object Detection Mosaic Augmentation :: YOLO v5 (2) | 2022.06.09 |
| [Python] mAP(mean Average Precision) 예시 및 코드 (1) | 2022.06.08 |
| [Python] albumentations 라이브러리를 이용한 Image Agumentation :: Bounding Box 좌표와 함께 이미지 변형하는 방법 (0) | 2022.05.06 |
| Object Detection이란? Object Detection 용어정리 (0) | 2022.03.31 |