YOLO Version별 비교
지난 포스팅에서 Object Detection 알고리즘 중 YOLO v1에 대해 자세히 알아보았다.
2022.04.04 - [AI/Object Detection] - [Object Detection(객체 검출)] YOLO v1 : You Only Look Once
[Object Detection(객체 검출)] YOLO v1 : You Only Look Once
지난시간에 Object Detection 이란 무엇인지 간단히 알아보고, 주요 용어들에 대해 알아보았다. 2022.03.31 - [AI/Object Detection] - Object Detection이란? Object Detection 용어정리 Object Detection이란? O..
leedakyeong.tistory.com
이번에는 version1부터 version6까지 어떻게 발전해왔는지 간략하게 알아보겠다.
YOLO v1 :: You Only Look Once: Unified, Real-Time Object Detection
Version 1은 2016년 5월에 개시된 논문으로, 자세한 설명은 이전 포스팅에 있으므로 한계점에 대해서만 설명하겠다.
1. Anchor Box를 사용하지않고, Cell 단위로 Bounding Box Regressor 과정을 통해 Box를 찾으므로 Localization Error로 인해 성능이 낮다.
Anchor Box란?
이미지에서 다양한 형태의 Object를 Detection하기 위한 미리 정해진 크기와 비율을 가진 Bounding Box.
단, Anchor Box의 개수와 형태(width, height 등)은 사용자가 임의로 정해주는 hyper parameter이다.
version1에서는 Anchor Box를 사용하지않고, Cell 단위에서 Bounding Box Regressor 과정을 통해 Box 사이즈를 Object에 맞도록 조정해주었다.

만약 한 장의 이미지에 자전거(3X4)와 강아지(1X2)가 있다고 했을 때 하나의 Box(1X1)를 가지고 늘렸다 줄였다 하면서 조정해 주는 일이 쉬운 일은 아니다.
따라서 여러 형태의 Anchor Box를 이용해 학습하는 것이 Localization에 더 유리하다.
Anchor Box의 예는 다음과 같다. 다양한 크기와 비율을 가진 Box들 중 내가 가진 데이터의 Ground Truth를 가장 잘 대변할 Anchor Box의 개수와 크기를 미리 지정해 모델에 넣어주면 된다.
아래 이미지에서는 파란색 Box가 Anchor Box로 가장 적합해 보인다.

2. 각 Grid Cell에 대해 2개의 Bounding Box를 찾지만, Classification은 한 개에 대해서만 수행한다. 따라서 겹치는 Object는 Detection하기 어렵다.

YOLO v1 마지막 Layer를 보면 BBox에 대한 값은 두 세트가 있지만, Classification에 대한 값은 한 세트만 존재한다.
3. 작은 물체에 대해서는 성능이 나쁘다.
마지막 layer의 size가 7by7로 매우 작아서 큰 물체는 잘 찾지만, 작은 물체에 대해서는 잘 못 찾는다는 단점이 있다.
단, Detection 속도가 아주 빠르다는 장점이 있다.
YOLO v2 :: YOLO9000: Better, Faster, Stronger
YOLO v2는 2017년 12월에 개시되었으며, v1에 몇 가지 아이디어를 추가하여 속도를 최대한 유지하면서 성능을 개선한 모델이다.
(정식 paper 이름은 YOLO9000으로, 실제 YOLO v2와 YOLO 9000에 대한 내용이 함께 들어있다.
YOLO 9000은 Classification 문제에 비해 Object Detection 문제는 예측 가능한 Class의 개수가 매우 적음을 지적하고, 이를 해결하기 위한 방법을 제시한다.
YOLO v2와 모델 자체는 거의 유사하므로 version 2에 대해서만 설명한다.)
YOLO v2의 개선 포인트는 다음과 같다.
1. 속도 개선
1-1. BackBone으로 Darknet 19 모델을 사용하여 속도를 빠르게 유지
* fps 45 -> fps 40

참고로 Darknet은 본 논문의 저자(Joseph Redmon)가 독자적으로 개발한 프레임워크로, DNN을 학습시킬 수 있는 툴이다. C언어로 작성된 오프소스로, 연산이 빠르고 설치가 쉬우며 CPU 및 GPU 연산을 지원한다는 특징이 있다.
2. 성능 개선
2-1. 모든 Conv Layer 뒤에 Batch Normalization 적용
Vanishing Gradient 문제를 해결하고, Learning Rate를 키울 수 있기 때문에 더 빨리 수렴할 수 있도록 해주고, Regularization 역할을 하기때문에 Dropout 등의 기법을 사용하지 않아도 된다는 장점이 있다.
Batch Normalization에 대한 자세한 설명은 여기 아주 잘 되어있다.
2-2. High Resolution Classifer
YOLO v1에서는 이미지 사이즈를 224by224로 pre-train Classifier 모델을 그대로 사용하고, 실제 입력을 받을 때는 448by448 사이즈의 고해상도 이미지를 사용했다.
YOLO v2에서는 이 점을 지적하고, Classfier를 똑같이 처음에는 224by224로 학습하고, 마지막 10 epoch정도는 448by448의 고해상도 이미지로 fine tuning 과정을 거친다.
단, 최종적으로 입력하는 이미지 사이즈는 416by416이다.
이는 최종 output feature map의 크기가 홀수가 되도록 하기 위함인데, 물체의 크기가 큰 경우 보통 가운데에 물체가 존재하기 때문에 feature map 내에 중심 cell이 존재할 수 있도록 하기 위함이다.
416by416 이미지를 넣었을 때 13by13의 feature map을 얻게 된다.
2-3. Convolutional with Anchor Boxes
각 Grid Cell에 대해 5개의 Anchor Box를 예측한다.
Box는 2개를 예측하고, Classification은 한 번만 수행했던 v1과 달리, 모든 Anchor Box에 대해 Classification을 수행한다.
즉, output tensor는 13X13X{(5+C)X5}가 된다. (여기서 C는 Class 개수를 의미한다.)
이로인해 mAP는 69.5에서 69.2로 감소하지만, recall은 81에서 88로 상승한다.
OD 문제에서 recall이 높다는것은 모델이 실제 객체의 위치를 예측한 비율이 높다는 것을 의미한다.
v1에서 recall값이 낮은 이유는 이미지 당 상대적으로 적은 수의 bounding box를 예측하기 때문이다.
v2에서는 anchor box를 통해 더 많은 수의 bounding box를 예측하면서 실제 객체의 위치를 더 잘 예측하고, 이로인해 recall 값이 상승하게 된다.
2-4. Dimension Cluster
위 Anchor Box의 개수와 크기는 고정이 아니라, 해결하고자 하는 데이터셋에 따라 GT를 가장 잘 대변할 수 있는 optimal anchor box를 탐색하여 결정한다. optimal anchor box를 탐색하는 방법은 K-means Clustering을 활용한다.

GT들의 width와 height로 K-means Clustering을 수행하고, 적절한 K개를 찾는다. YOLO v2에서는 K를 5로 정했고, 이게 Anchor Box의 개수가 된다.
그리고, 각 Cluster의 center point가 Anchor Box의 사이즈가 된다.
단, Clustering의 기준을 유클리디안 거리가 아닌, IOU를 기준으로 한다.
K-means Clustering의 기준을 Euclidean Distance로 하지 않고, IOU로 하는 이유는
만약, 아래 이미지에서 유클리디안 거리를 기준으로 유사도를 측정한다면 실제로는 왼쪽 박스들이 더 유사하지만, 오른쪽 박스들이 더 유사하다고 계산될 것이다.
따라서 유클리디안 거리가 아니라, IOU를 기준으로 Cluster를 구한다.

2-5. Direct Location Prediction
Box에 Sigmoid함수를 적용하여 Box의 중심점이 Cell 내에 존재하도록 한다.
이를 적용하지 않으면, Box가 Cell을 벗어나 아무 위치에나 존재할 수 있어, 학습 초기 iteration 시 모델이 불안정하기 때문이다.

위 이미지에서 검정색 점선 Box가 미리 지정해 준 Anchor Box이고, 파랑색 Box가 예측하고자 하는 Box이다.
이 주어진 Anchor Box의 Width, Height를 조정하여 Bounding Box를 예측한다.
Cell의 시작점이 (Cx, Cy)이고, Sigmoid를 취한 tx, ty만큼 움직여 Bounding Box의 center point를 조정해준다. 단, Sigmoid를 취했으므로 0~1사이만큼만 움직여 주기 때문에 무조건 해당 cell 안에 center point가 존재하게된다.
그리고 주어진 Pw, Ph에 exponential취한 tw, th만큼 곱해 width와 height도 조정해준다.
최종적으로 bx, by, bw, bh를 예측하는 것이 목적이나, 모델은 애초부터 b_를 예측하도록 학습하는 것이 아니라, t_를 예측하도록 학습하고, 이를 변형하여 b_를 도출하게 된다.
2-6. Fine-Grained Features
YOLO v2는 input image size가 416by416일 때, 최종적으로 13by13 feature map을 출력한다.(v1은 7by7 feature map을 출력한다.)
이처럼 feature map의 크기가 작을 때 큰 물체는 잘 예측하지만, 작은 물체는 예측하기 어렵다는 문제가 있다.
실제로 YOLO v1에서도 작은 물체를 잘 Detection 하지 못한다는 단점이 있었다.
이를 해결하기 위해 Passthrogh layer를 추가했다.
이는 High Resolution feature map은 작은 물체를 잘 예측하고, Low Resolution feature map은 큰 물체를 잘 예측한다는 특징을 활용한 layer이다.
아래 그림처럼 26X26X512 feature map은 high resolution으로, 작은 물체를 잘 예측할 수 있으므로, 이 feature map을 활용해 4개로 나누어 concat한다. 그럼 13X13X2048 사이즈의 feature map이 생성되고, 이를 13X13X1024 feature map과 concat한다.
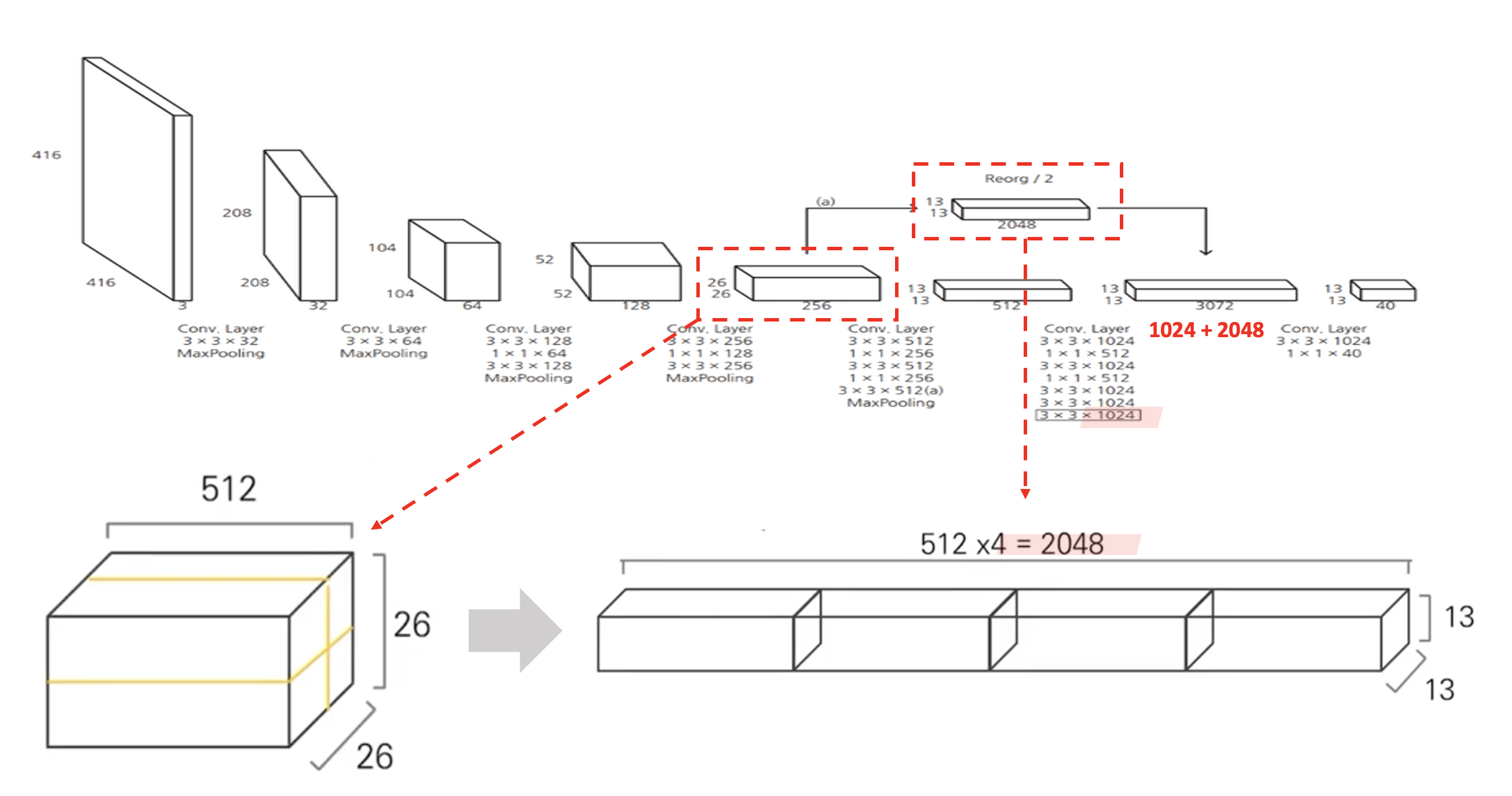
이를 통해 YOLO v1보다 작은 물체도 잘 예측할 수 있도록 했다.
2-7. Multi-Scale Training
version1은 마지막에 Fully Connetecd Layer를 사용했는데, version2에서는 이를 CNN Layer로 변경했다.
이로인해 파라미터 수를 감소시키고, 속도도 빠르게 수행할 수 있도록 했으며, Input 이미지 사이즈에 변화가 가능하도록 했다.

다양한 Size의 이미지에도 Robust한 Detection 성능을 내기 위함이고, 실제 10 batch 마다 random 하게 이미지 사이즈를 변경하여 학습했다. (단, 1/32로 down sampling되기 때문에 input size는 32의 배수여야한다.)
v2의 저자는 이와같이 성능을 개선하기 위해 7가지 기술들을 적용했고, 아래 이미지는 각 기술을 적용함에 따라 mAP가 어떻게 변화했는지를 보여주는 표이다.

기존 YOLO에 비해 엄청난 성능향상을 이뤘지만, 여전히 작은 물체에 대해서는 성능이 낮았다.
YOLO v3 :: An Incremental Improvement
YOLO v3는 2018년 4월에 개시되었으며, 역시 v2에 몇 가지 아이디어를 더해 성능을 개선한 모델이다.
(v3는 엄밀이 말하면 paper는 아니고 Tech Report로 작성되었다.
실제 저자도 "I managed to make some improvements to YOLO. But, honestly, nothing like super interesting, just a bunch of small changes that make it better." 라 표현하고있다.)
이전 버전 모델과 달라진 점 위주로 설명하겠다.
1. Multilabel Classification
실제 어떤 물체가 사람이면서 동시에 여성일수도 있다. 즉, 한 물체에 대해 multi classlabel을 가질 수 있다. 따라서 version3에서는 이것이 가능하도록 마지막에 softmax가 아닌 모든 class에 대해 sigmoid를 취해 각 class별로 binary classification을 하도록 바꾸었다.
2. Backbone으로 Darknet -53 사용
Darknet-19를 사용했던 v2와 달리 Backbone으로 Darknet-53을 사용한다.
Architecture는 다음과 같다.
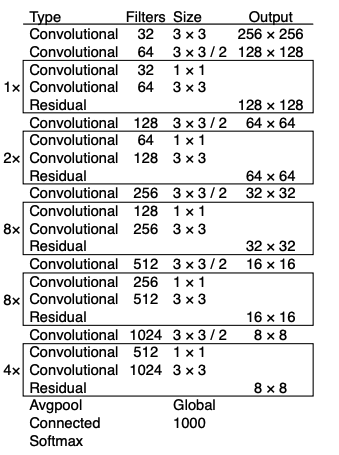
Darknet-19에 비해 더 깊어진 모델이라 정확도는 상승했지만, 속도는 떨어졌다.
3. Predictions Across Scales
YOLO v1부터 small object를 잘 예측하지 못한다는 문제가 지속되어왔다.
이를 해결하기 위해 v3는 prediction feature map으로 3개의 Scale을 사용한다.
v2에서처럼 작은 사이즈의 Feature map은 큰 물체를 잘 Detection하고, 큰 사이즈의 Feature map은 작은 물체를 잘 Detection한다는 개념은 동일하다.
만약, 416by416 이미지를 input으로 넣었을 때,
13by13 size의 feature map에서 큰 이물을 Detection하고,
26by26 size의 feature map에서 중간 크기의 이물을 Detection하고,
52by52 size의 feature map에서 작은 이물을 Detection한다.
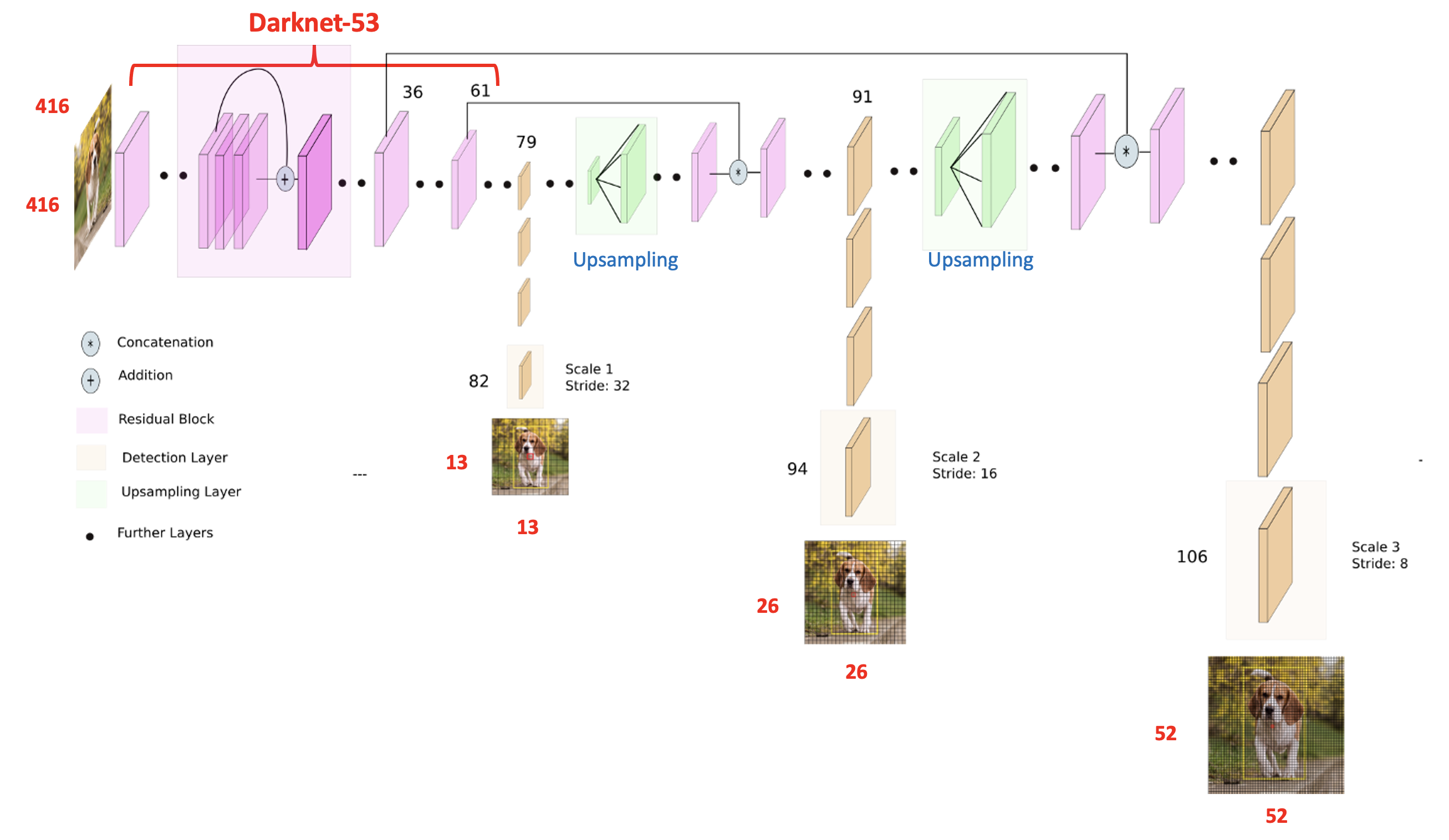
v2와 마찬가지로 FC layer가 없으므로 input size는 32의 배수로 자유롭게 넣어줄 수 있다.
prediction 후 feature map을 Upsampling 하고 이전에 사용했던 feature map과 통합하여 더 풍부한 정보로 사용한다.
Anchor Box는 각 Scale별로 3개씩 총 9개를 사용했으며, 개수와 크기는 v2와 동일하게 K-means를 통해 결정한다.
따라서 한 Scale 당 output tensor는 NXNX{(5+C)X3}이 된다. (C는 Class의 개수를 의미한다.)
* 참고로 version 1, 2, 3에 대해 bounding box의 개수를 비교하면 다음과 같다.
version2 ,3의 input size는 416by416이라 가정한다.
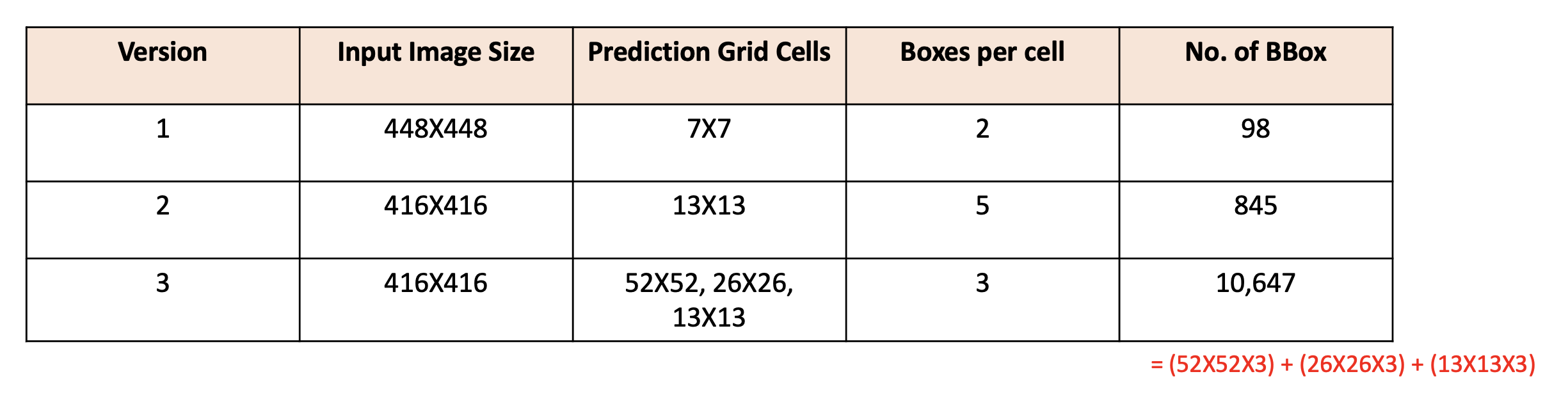
version3에서 예측하는 BBox의 수가 version2에 비해 10배가 넘는다.
따라서 속도는 줄지만, 성능은 좋아질 수 있었다.
version4부터는 다음 포스팅에 이어가겠다.
참고
Anchor Box : https://velog.io/@dltjrdud37/Object-DetectionRCNN
Batch Normalization : https://www.youtube.com/watch?v=m61OSJfxL0U&t=440s
YOLO v2 : https://herbwood.tistory.com/17, https://www.youtube.com/watch?v=vLdrI8NCFMs
YOLO v3 : https://www.youtube.com/watch?v=HMgcvgRrDcA, https://deep-learning-study.tistory.com/509
'AI > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv5, YOLOv6 Loss 구하는 과정 중 build_targets() 이해하기 (2) | 2022.08.04 |
|---|---|
| [Object Detection] YOLO v1 ~ v6 비교(2) (8) | 2022.06.23 |
| [Python] Object Detection Mosaic Augmentation :: YOLO v5 (2) | 2022.06.09 |
| [Python] mAP(mean Average Precision) 예시 및 코드 (1) | 2022.06.08 |
| [Python] albumentations 라이브러리를 이용한 Image Agumentation :: Bounding Box 좌표와 함께 이미지 변형하는 방법 (0) | 2022.05.06 |