YOLOv5와 YOLOv6는 같은 개발자가 개발한 버전으로, 두 버전 모두 여기에 구현되어 있다.
두 버전 모두 loss는 계산하는 과정은 같은데, loss를 계산하기 위해 label을 각 Grid에 맞게 build하는 과정을 파해쳐보려한다.
YOLO v1 포스팅에 자세히 설명한 것 처럼 Ground Truth의 Center point가 위치하는 Grid를 표시하여 이로 Obj Loss를 구하고,
GT의 Width, Height를 Grid에 맞게 Normalization 한걸로 Box Loss를 구한다.
build_targets()는 이를 구현하는 과정이다.
이를 이해하려면 YOLO는
1. grid를 나누어 각 grid별로 classification과 BBox Regression을 하고, 따라서 각 grid에 대해 loss를 구한다는 것을 이해해야하고
2. YOLO v3부터 3개 Scale로 Prediction한다는 것을 알고있어야 한다.
이 내용들은 모두 이전에 YOLOv1~v6에 대해 포스팅한 내용에 포함되어있다.
2022.04.04 - [AI/Object Detection] - [Object Detection(객체 검출)] YOLO v1 : You Only Look Once
2022.06.23 - [AI/Object Detection] - [Object Detection] YOLO v1 ~ v6 비교(1)
2022.06.23 - [AI/Object Detection] - [Object Detection] YOLO v1 ~ v6 비교(2)
[Object Detection] YOLO v1 ~ v6 비교(2)
YOLO Version별 비교 지난 포스팅에서 YOLO v1~v3를 비교&리뷰했다. 2022.06.23 - [AI/Object Detection] - [Object Detection] YOLO v1 ~ v6 비교(1) [Object Detection] YOLO v1 ~ v6 비교(1) YOLO Version별 비..
leedakyeong.tistory.com
[Object Detection] YOLO v1 ~ v6 비교(1)
YOLO Version별 비교 지난 포스팅에서 Object Detection 알고리즘 중 YOLO v1에 대해 자세히 알아보았다. 2022.04.04 - [AI/Object Detection] - [Object Detection(객체 검출)] YOLO v1 : You Only Look Once [Ob..
leedakyeong.tistory.com
[Object Detection(객체 검출)] YOLO v1 : You Only Look Once
지난시간에 Object Detection 이란 무엇인지 간단히 알아보고, 주요 용어들에 대해 알아보았다. 2022.03.31 - [AI/Object Detection] - Object Detection이란? Object Detection 용어정리 Object Detection이란? O..
leedakyeong.tistory.com
파해쳐볼 이 코드는 loss를 계산하는 yolov5 > util > loss.py에 build_targets()로 구현되어있다.
먼저 필요한 라이브러리들을 불러와준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import sys
sys.path.insert(0, 'PATH of YOUR yolov5')
import os
import cv2
from models.yolo import Model
import torch
import torch.nn as nn
from utils.metrics import bbox_iou
from utils.torch_utils import de_parallel, select_device
from utils.loss import ComputeLoss
from models.experimental import attempt_load
from PIL import Image
|
cs |
개발자가 github에 올려놓은 yolov5 코드를 로컬에 다운받아주고, 그 경로를 PATH of YOLOR yolov5에 넣어준다.
개발자가 구현해놓은 다른 function들을 import해서 쓰기 위함이다.
다음으로 build_targets()에 parameter로 전달해주어야 하는 prediction값과 target값을 만들어준다.
본인의 모델과 이미지, label을 불러와준다.
학습한 모델이 없다면, 기본으로 제공하는 COCO dataset에 pretrain된 모델을 불러와주어도 좋다.
(본인은 YOLOv6 small모델을 사용한다.
참고로, YOLOv5는 3개 Scalse로 Prediction하고, YOLOv6는 4개 Scale로 Preidiction한다.)
|
1
2
3
4
|
weights = "PATH of YOLOR Model(.pt)"
device = select_device('cpu')
model = attempt_load(weights, inplace=True, fuse=True)
|
cs |
|
1
2
3
4
5
6
7
8
|
img = cv2.imread("PATH of YOUR jpg Image")
img = cv2.resize(img, (128,128), interpolation=cv2.INTER_AREA)
im = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
im = torch.from_numpy(im)
im = im.float()
im /= 255
|
cs |
본인은 128by128 size로 이미지를 넣을거기 때문에 resize도 해주었다.
(YOLOv5, v6모두 input image의 사이즈는 32의 배수여야한다.)
그리고 Model에 input으로 넣기 위해 RGB channel 순서를 바꿔주고, Normalization도 해주었다.
불러온 image에 맞는 label도 불러와준다. label은 다음과 같이 class, x, y, w, h로 되어있고 xywh는 0~1사이로 normalize된 값이다.
|
1
|
labels = np.loadtxt("PATH of YOUR txt Label Path", ndmin = 2)
|
cs |

즉, 128by128 이미지에 8.96(=0.07*128)by14.08(=0.11*128) 크기의 물체가 center poin xy 좌표 (39.04(=0.305*128), 28.8(=0.225*128))에 위치하고있다.
이제 불러온 모델에 불러온 image를 넣어 prediction값을 뽑아준다.
|
1
|
pred = model(im[None])
|
cs |
결과는 2개로 구성된 tuple type이 return되는데, 이 중 두 번째 값을 사용한다.
각각의 값이 어떤건지는 yolov5 > models > yolo.py 에 Detect Class 중 forward() 를 보면 알 수 있다.
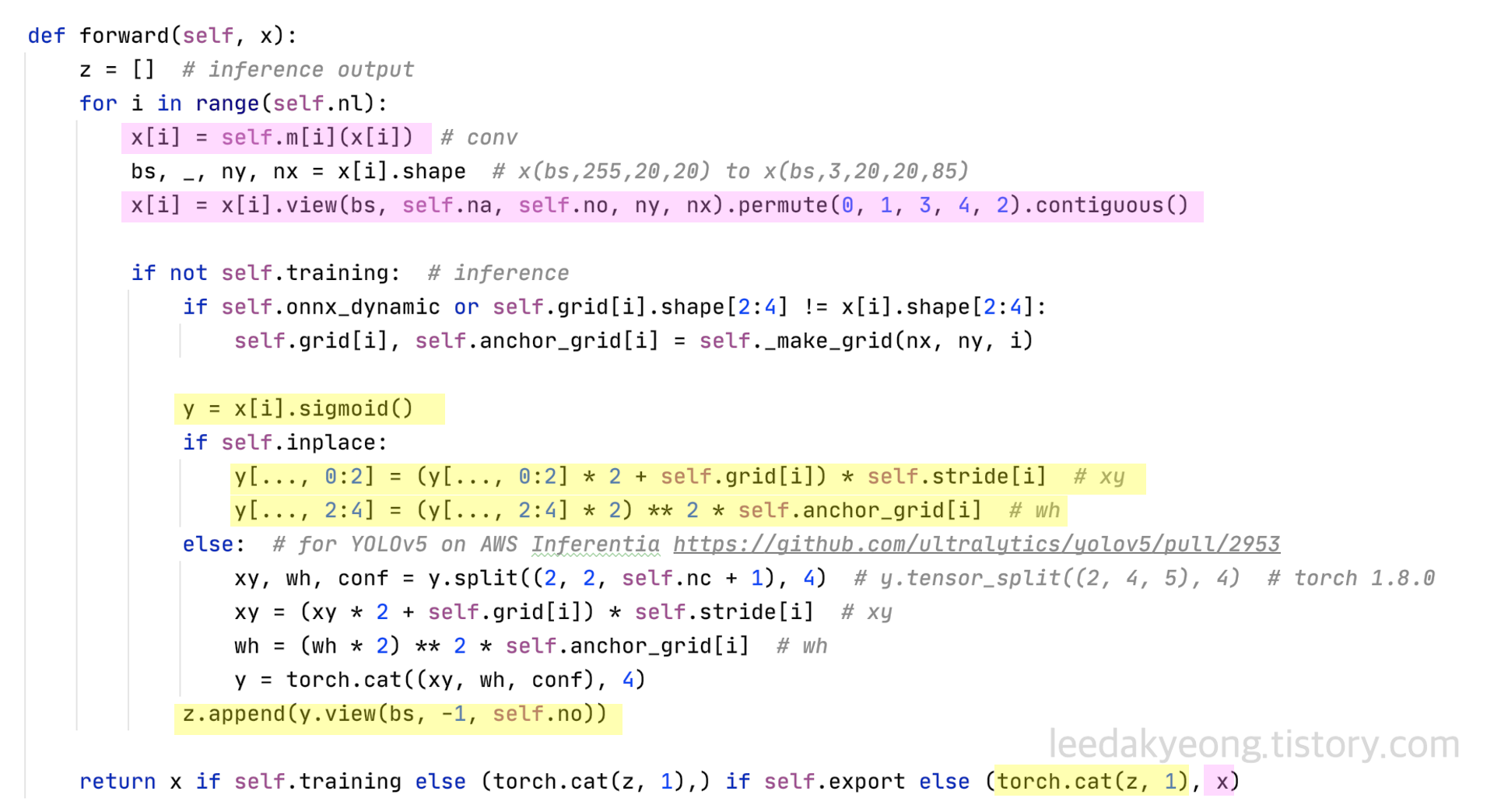
return된 값 중 첫 번째 값은 실제 inference 할 때, NMS에 들어가는 값으로, 모든 layer를 다 통과 한 후 sigmoid 취하고, xywh 좌표를 각 grid 별 anchor에 대해 처리한 결과이다.
두 번 째 결과는 학습할 때 loss 계산 시 사용하는 값으로, 모든 layer 통과 후 sigmoid 취하기 전 값이다.
이렇게 prediction한 결과 중 loss 계산 시 사용한 두 번째 결과의 shape은 다음과 같다.

총 4개 scale별로 prediction한 결과이므로 4개의 결과를 담고있고,
input으로 들어간 이미지가 1장이므로 첫 번째 값은 1,
Anchor Box가 각 Scale별로 3개씩 있으므로 두 번째 값은 3이다.
세 번째, 네 번째 값은 각 Scale의 Grid 개수이고,
마지막 값은 예측값을 포함하고 있다. 본인은 class개수가 5개이므로 5개 + Box coordination 5개(xywh, confidence score) 해서 10개값을 가지고있다.
numpy인 label을 torch로 바꾸어주고, 첫 번째 자리에 img_id를 추가해준다.
|
1
2
3
|
labels_out = torch.zeros((1, 6))
labels_out[:, 1:] = torch.from_numpy(labels)
targets = labels_out # image, class, xywh
|
cs |
만들어진 targets는 다음과 같다.
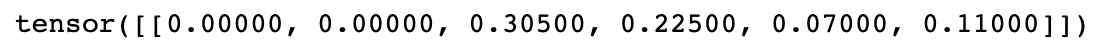
build_targets() 결과를 먼저 확인해보면 다음과 같다.
|
1
2
3
4
|
compute_loss = ComputeLoss(model)
p = pred[1]
tcls, tbox, indices, anch = compute_loss.build_targets(p, targets)
|
cs |
tcls부터 각각 결과는 다음과 같다.

4개 Scale로 예측하고, 각 Scale은 3개의 Anchor를 가지고 있기 때문에 모든 결과는 4개, 각각은 다시 3개로 구성되어있다.
각각에 대해 아래서 더 자세히 설명하겠지만, 미리 보자면
1. tcls는 true label의 class를 나타내고
2. tbox는 true label의 center point를 포함하고 있는 grid cell에서의 normalize된 xywh 좌표를 나타내며, 이 내용은 YOLOv1 설명한 포스팅에 아주 자세히 나와있다.
실제 center point를 포함하는 grid는 딱 하나인데, 세개의 좌표를 return한 이유는 아래서 설명하겠다.
3. indices center point를 포함하는 grid cell의 위치를 나타내며,
첫 번째 [0,0,0]는 0번째 이미지임을,
두 번째 [0,0,0]는 true class를,
[3,3,4], [4,5,4]는 center point를 포함하는 grid cell의 위치를 나타낸다. 위에서부터 3번째, 왼쪽에서부터 4번째에 위치한다고 해석하면 된다.
전체 코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=self.device) # normalized to gridspace gain
ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor(
[
[0, 0],
[1, 0],
[0, 1],
[-1, 0],
[0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
],
device=self.device).float() * g # offsets
for i in range(self.nl):
anchors = self.anchors[i]
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain # shape(3,n,7)
if nt:
# Matches
r = t[..., 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
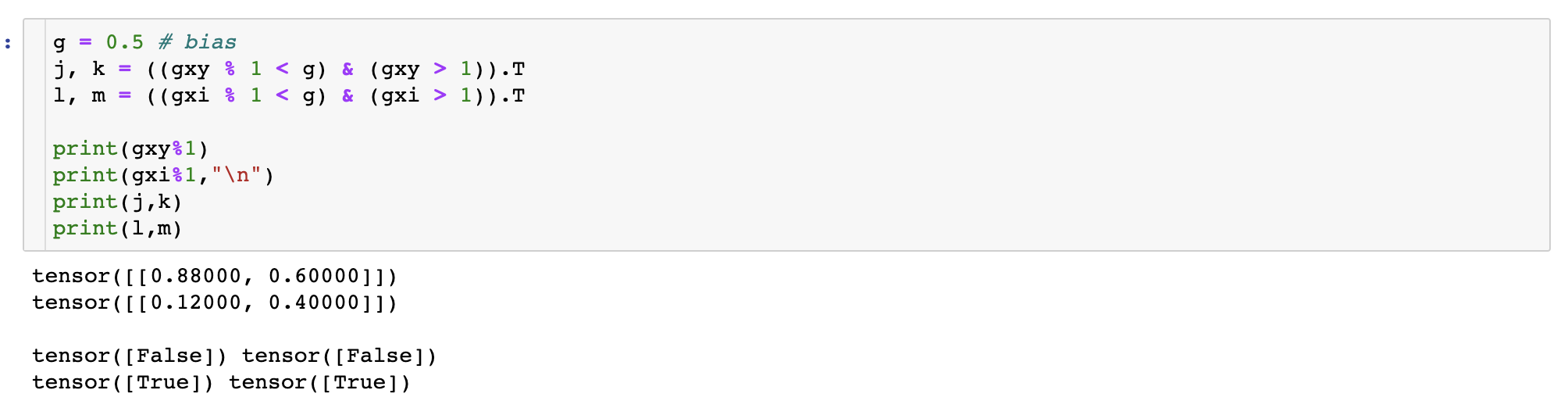
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
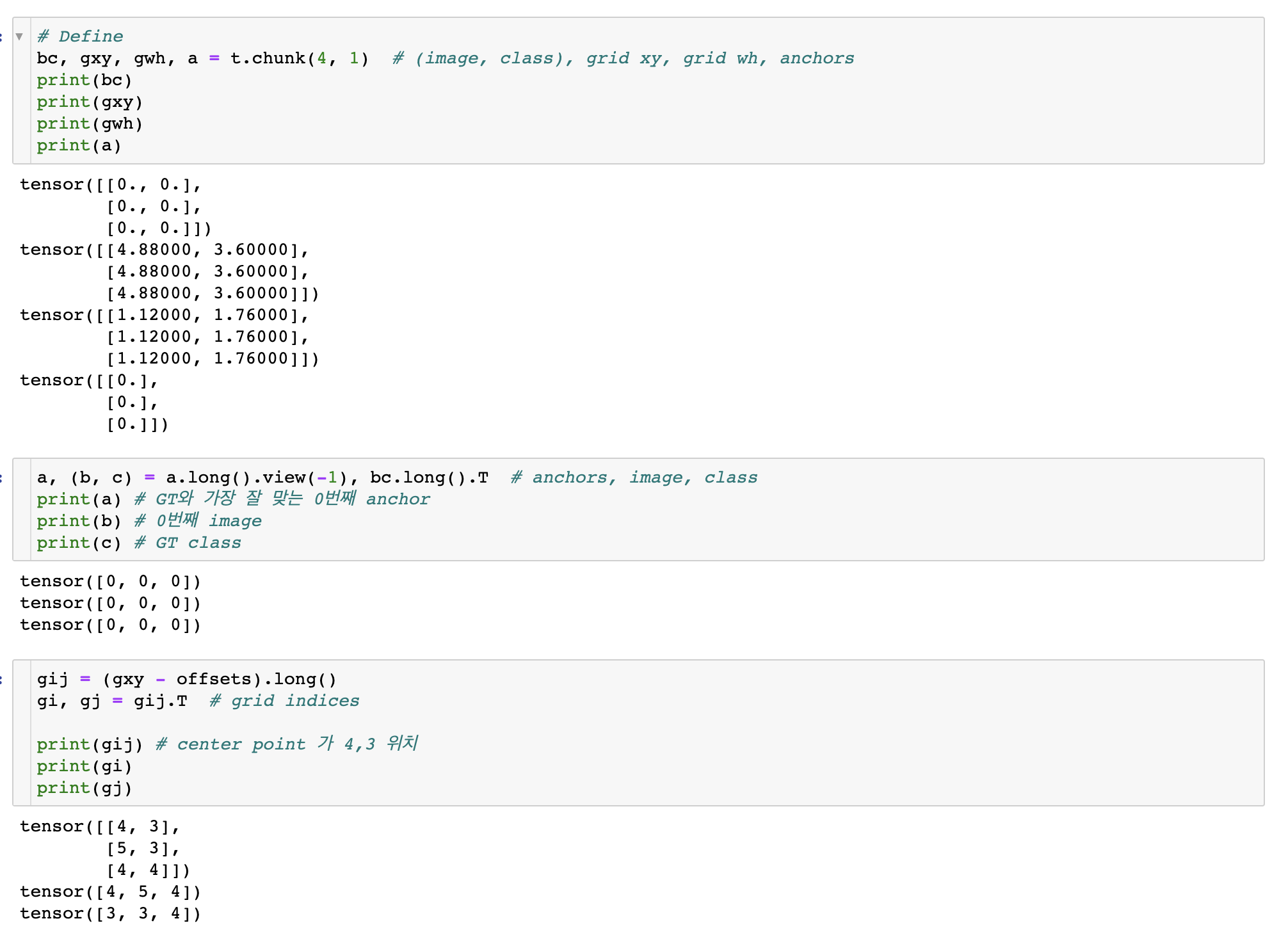
bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
gij = (gxy - offsets).long()
gi, gj = gij.T # grid indices
# Append
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch
|
cs |
이제 하나하나 뜯어보겠다.
먼저 na는 anchor의 개수 즉, 3개이고 nt는 target의 shape 즉, 해당 이미지에 몇 개의 물체가 있는지 이다.

결과를 저장할 list들을 선언해주고, anchor가 3개이므로 target도 3개로 바꾸어준다.
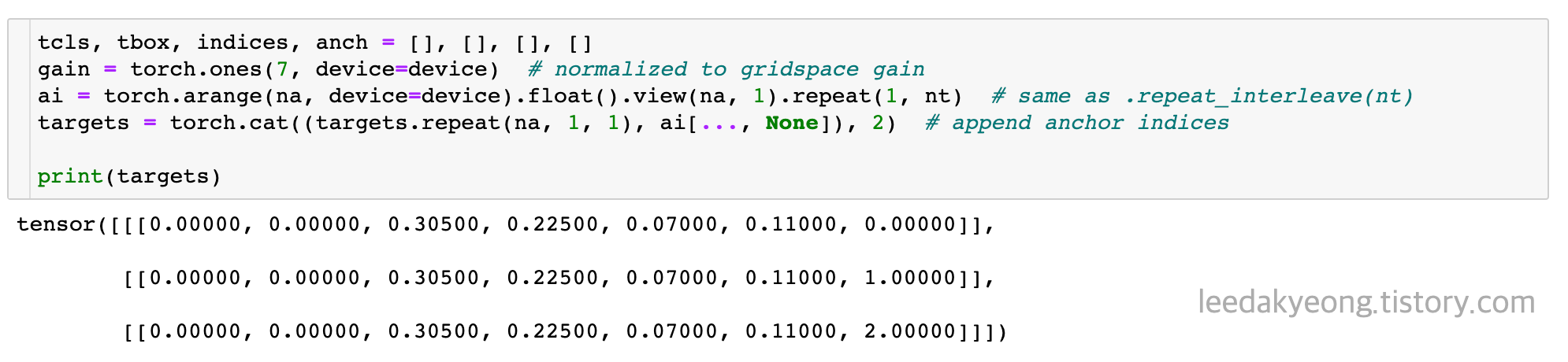
offsets를 지정해주는데, 실제 한 물체에 대해 center poin를 포함하는 grid는 딱 한 개 인데 나중에 3개의 결과가 나오는 이유가 바로 이것 때문이다. 자세한 설명은 아래서 하겠다.

이제 for loop로 들어가 i=0일 때에(첫 번째 Scale) 대해서 설명하겠다.
(총 4개 scale로 prediction하기 때문에 for loop는 총 4번 돌아간다.)
model의 마지막 Layer인 Detect Layer만 따로 저장한다.
4개 scale에 대해 3개씩 anchor가 구성되어있으며 각각의 w,h는 다음과 같다.
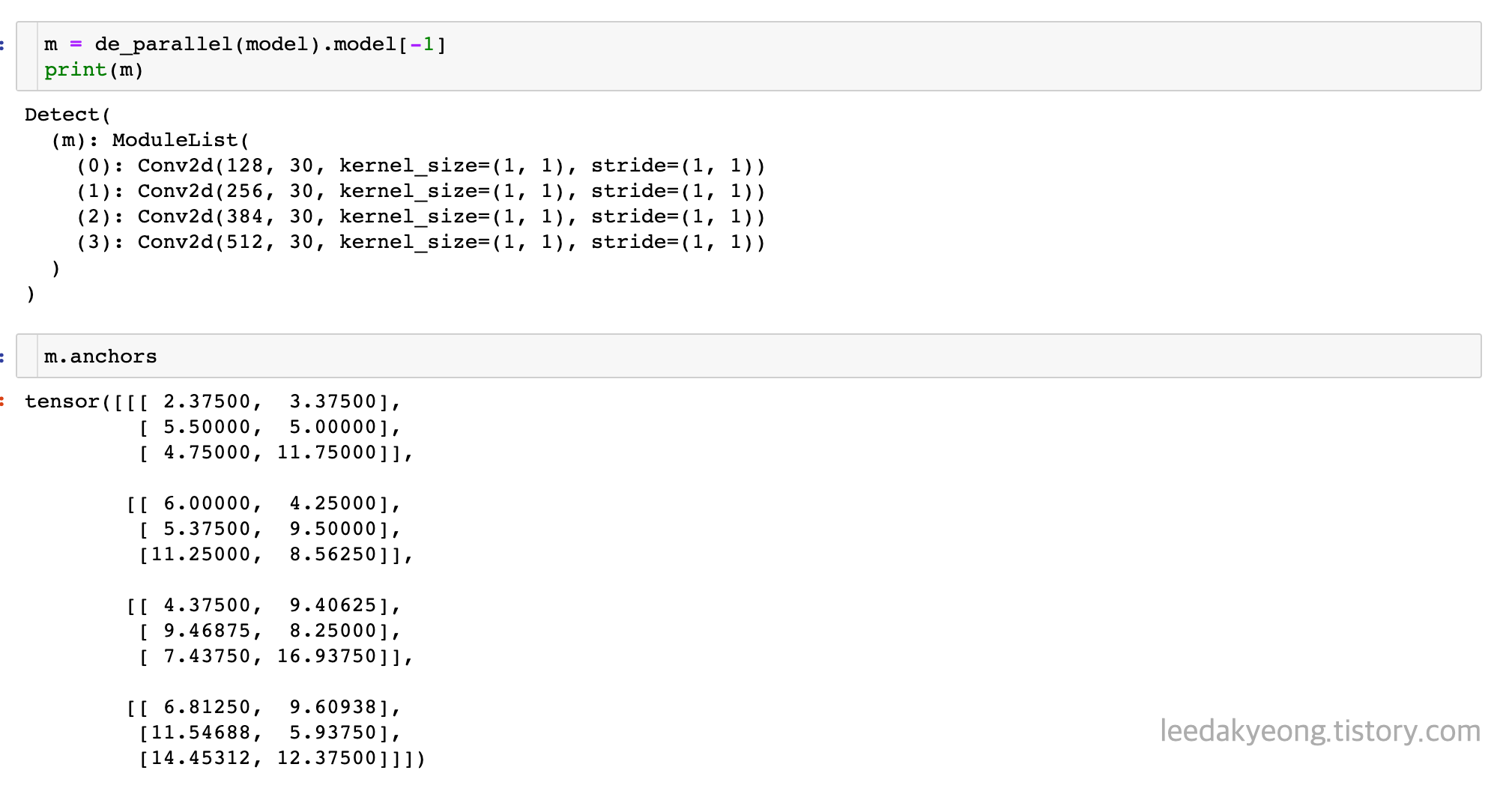
i=0 넣어주고, 첫 번째 scale에 해당하는 anchor만 가져온다.
첫 번째 scale의 예측값은 16by16 grid이므로 이를 gain에 반영한다.
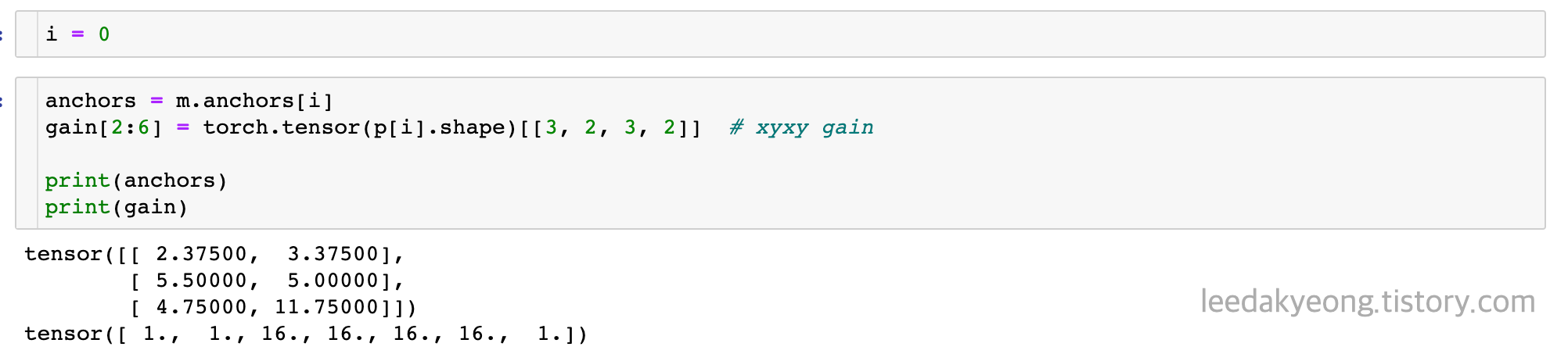
targets와 gain을 곱한다.
현재 targets는 전체 이미지 크기에 대해 0~1로 Normalize된 xywh값이므로 16by16이 되었을 때 실제 이물의 크기로 바꿔주기 위함이다.

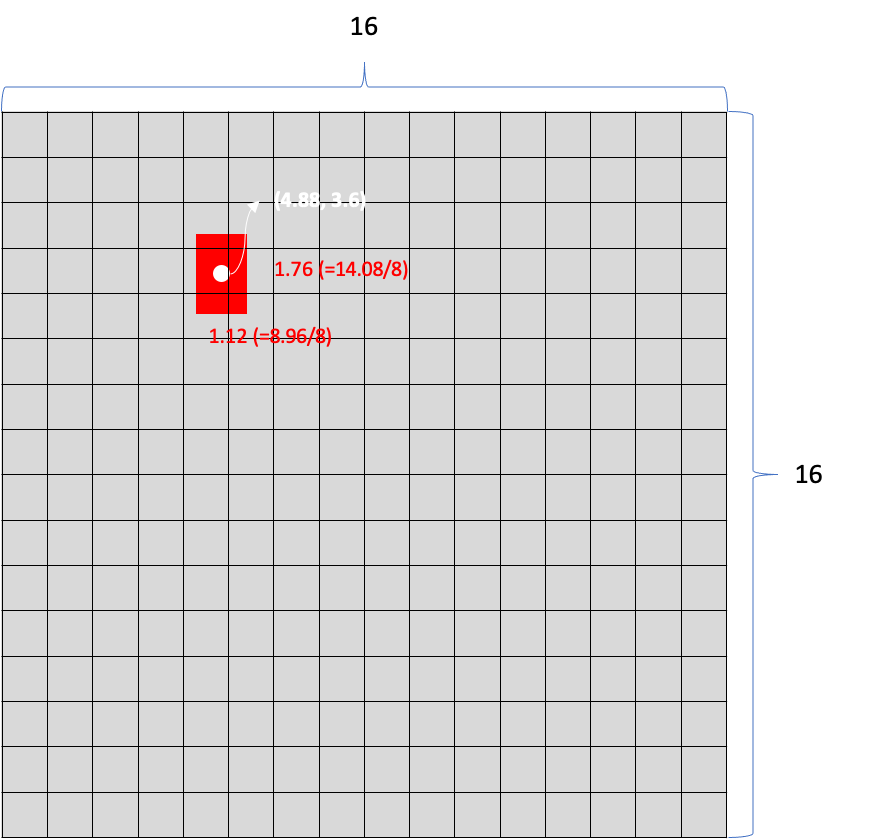
이를 그림으로 표현하면 다음과 같다.
(4.88, 3.6) 은 16by16일 때 center point의 xy 좌표를 의미하며, (1.12, 1.76)은 한 칸의 w,h 대비 물체의 w,h가 몇배인지를 의미한다.
(128by128이 16by16이 되었으므로 한 칸의 w,h는 8이다.)
이제 3개의 anchor 중 해당 물체를 가장 잘 표현하는 anchor를 찾는다.


4.0은 hyper parameter 값이다.
3개의 anchor box 중 anchor box w,h와 물체 w,h의 비율이 4배가 되지 않는 anchor box를 찾는다.
첫 번째 anchor 만 True임을 확인할 수 있다.
실제 첫 번째 scale의 3개 anchor box와 물체의 크기는 다음과 같다.

세 가지 anchor 중 첫 번째 anchor만 유효하므로 3개로 늘려주었던 target 중 첫 번째만 불러오고,
16by16 grid에서 왼쪽 위부터 시작한 center xy 좌표(gxy)와 오른쪽 아래부터 시작한 xy좌표(gxi)를 계산한다.

그리고 center point를 포함하는 grid는 한 개있는데, 세 개를 return한 이유가 바로 지금 나온다.
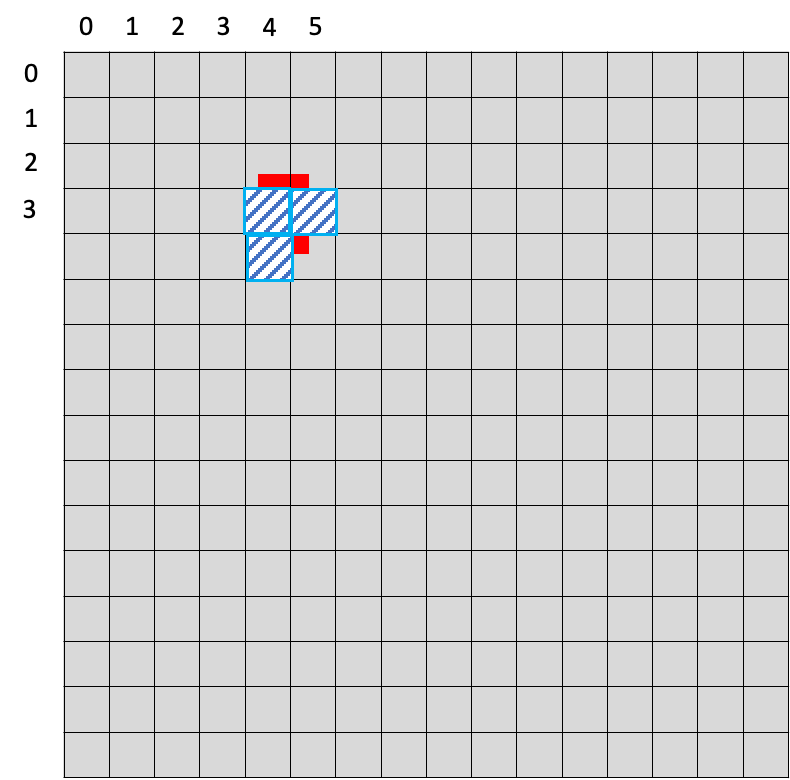
물체의 center poin를 포함하고 있는 grid를 확대해서 4분면으로 갈라보면 다음과 같다.
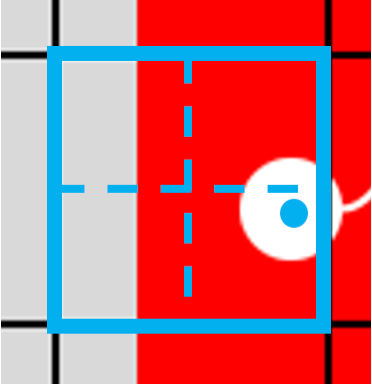
center point는 4분면 중 오른쪽 아래 위치한다.
따라서 위 코드에서 j,k,l,m 중에 l과 m만 True이다.
이는 현재 cell의 오른쪽 cell과 아래 cell도 GT 영역에 포함해주기 위함이다.
즉, Center point를 포함하는 딱 하나의 Grid가 아니라, GT를 포함하고 있는 모든 Grid를 반영해주기 위함이다.
따라서 실제 center point를 포함하고 있는 cell, 4분면으로 갈랐을 때 center poin가 있는 부분을 기준으로 두 개 더 추가해서 총 3개의 grid cell이 return되었던 것이다.
이를 정리하면 다음과 같다.
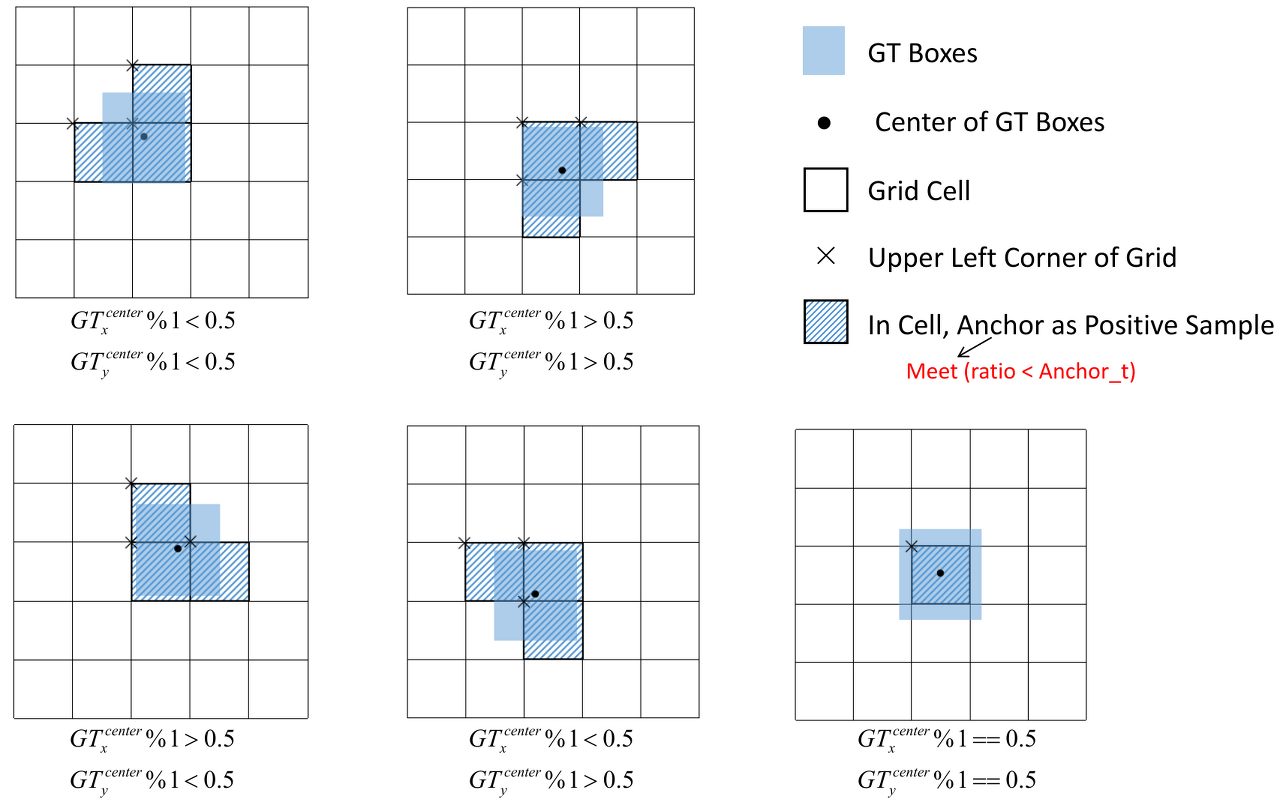
지난 YOLO들에서는 Center point가 포함된 딱 하나의 Grid만 Loss를 구하는데 사용했지만,
이제는 실제 Ground Truth를 포함하는 모든 Grid를 Loss에 반영한다는 것이 큰 특징이다.
이제 원래 grid cell을 포함하여 두 개의 grid cell 위치를 True/False로 표현하고 target도 맞춰서 가져온다.
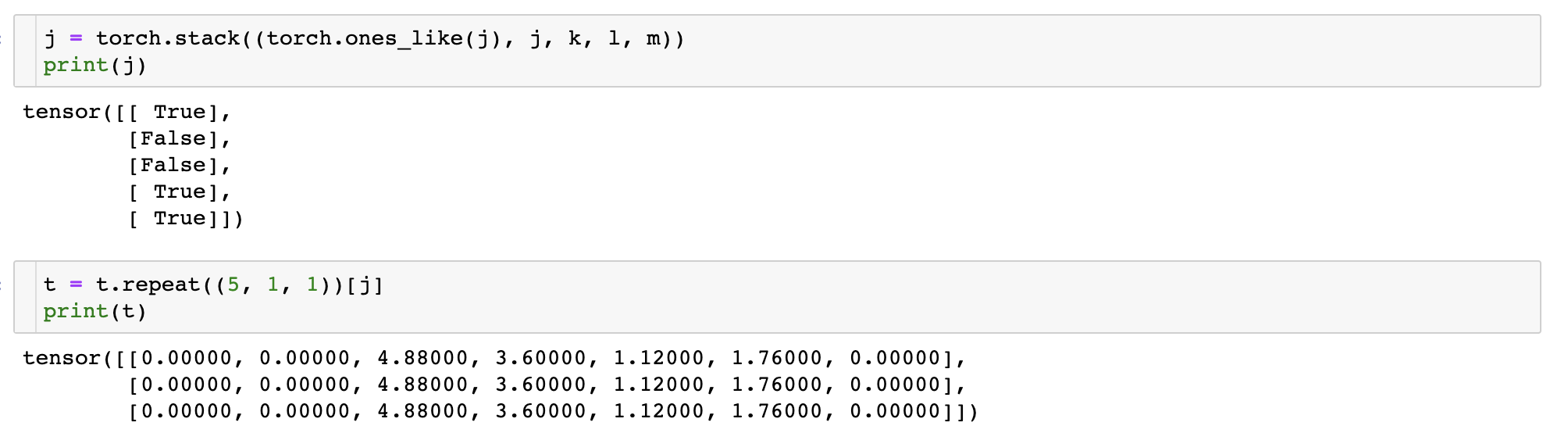
이제 나머지 두 cell에 대해서도 normalize된 좌표를 계산해야하므로 위에서 미리 구해두었던 offsets 에서도 맞는 값만 뽑아온다.

이제 각 grid cell의 위치(indices)를 계산한다.
마지막 결과를 보면
[왼쪽부터 4번째, 위에서부터 3번째]
[왼쪽부터 5번째, 위에서부터 3번째]
[왼쪽부터 4번째, 위에서부터 4번째] (단, 0부터 시작)
grid cell을 표시하고 있다.
최종적으로 결과 list에 append해주면 끝이다.

참고로 tbox는 각 cell에 대해 center point를 normalize해 준 값이다.
이제 이 결과들은 loss를 계산하는데 사용한다.
'AI > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLO Define Optimal Anchor Box :: YOLO v5, YOLO v6 autoanchor (0) | 2022.08.30 |
|---|---|
| [Object Detection] YOLO v5, v6 Loss (3) | 2022.08.10 |
| [Object Detection] YOLO v1 ~ v6 비교(2) (8) | 2022.06.23 |
| [Object Detection] YOLO v1 ~ v6 비교(1) (6) | 2022.06.23 |
| [Python] Object Detection Mosaic Augmentation :: YOLO v5 (2) | 2022.06.09 |