YOLO에서 Optimal 한 Anchor Box 정의하는 방법(with k-means & GA)
in YOLOv5, YOLO v6
YOLO 에서 Bounding Box를 예측하기 위해 Anchor Box를 사용하는데,
2-stage 기법에서는 COCO dataset이나 Pascal VOC dataset에 맞춘 Anchor Box를 그대로 사용한다면,
YOLO에서는 학습하고자 하는 dataset에 맞는 Anchor Box를 k-means와 Genetic Altorithm으로 새로 정의하여 사용한다.
이번 포스팅에서는 YOLO v5, v6 개발자가 구현해놓은 코드를 기반으로 그 방법을 설명하고자 한다.
먼저 필요한 라이브러리들을 불러온다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import sys
sys.path.insert(0, 'Path of your yolov5 directory')
import os
import random
from pathlib import Path
import numpy as np
import torch
import torch.nn as nn
import yaml
from torch.cuda import amp
from tqdm import tqdm
import val # for end-of-epoch mAP
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.dataloaders import create_dataloader
from utils.downloads import attempt_download
from utils.general import (LOGGER, colorstr, intersect_dicts, emojis)
from utils.metrics import fitness
|
cs |
그리고 Pretrain 된 모델을 불러온다. 이 과정은 현재 anchor 가 어떻게 구성되어있는지와, 그 anchor box가 현 dataset과 얼마나 적합한지를 알아보기 위함으로 생략해도 되는 과정이다.
본인은 v6의 small 모델을 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
weights = "Path of your yolov5s6.pt"
weights = attempt_download(weights)
ckpt = torch.load(weights, map_location='cpu') # l]d checkpoint to CPU to avoid CUDA memory leak
device = "cpu"
nc = 13
model = Model(ckpt['model'].yaml, ch=3, nc=nc).to(device) # create
exclude = ['anchor']
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
|
cs |
학습에 사용할 dataset도 불러온다.
이미지는 128 by 128 size로 변형하여 사용할 예정이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
hyp = "Path of your hyp.yaml(hyp.scratch-low.yaml)"
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f)
train_loader, dataset = create_dataloader(path = "Path of your image dataset directory",
imgsz = 128,
batch_size = 16,
stride = max(int(model.stride.max()), 32),
single_cls = False,
hyp=hyp,
augment=False,
cache=False,
rect=False,
rank=-1,
workers=1,
image_weights=False,
quad=False,
prefix=colorstr('train: '),
shuffle=False)
|
cs |
COCO Dataset에 Pretrain된 model(yolov5s6.pt)의 anchor box는 다음과 같다.

Detect layer인 마지막 layer만 불러오면 확인해 볼 수 있다.
이 값들은 1280 by 1280 size 기준으로 만들어진 값들이고, Detection Scale이 4개라서 anchor box 역시 4 set으로 이루어져있다.
각 Scale별로 3개씩 총 12개이며, 순서대로 [width, height]를 의미한다.
새로운 anchor box들을 정의하기전에, 현재 anchor box가 본 dataset에 얼마나 적합한지 수치화해 볼 수 있다.
현재 anchor box와 상관없이 새로운 anchor box를 정의하고 싶다면 이 과정은 넘어가도 된다.
단, train.py 코드 실행시에는 필수로 실행되는 코드로, 여기서 return되는 값이 일정 값 이하이면 새로운 anchor box를 정의하고, 그렇지 않으면 그대로 사용한다.
먼저, image size를 원하는 크기로 resize하고, 물체의 크기(width, height)도 그 size에 맞게 resize한다.
|
1
2
3
4
5
6
|
imgsz = 128
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True) # 128으로 바꾼 이미지 사이즈
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float()
# 128로 resize 후 물체의 width, height
|
cs |
그리고 현재 anchor box와 resize한 dataset이 얼마나 적합한지 확인하는데,
이는 전체 anchor box들 중 가장 적합한 하나의 anchor box를 찾고, 그 box의 w,h와 물체의 w,h의 비율이 threshold를 넘지않는 물체의 비율을 계산한다. (예를들면, 2배를 넘지않는 비율)
이를 best possible recall이라 부른다.
코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
|
thr = 2.0
def metric(k):
# bpr = k로 낼 수 있는 최대 성능(recall)
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric # w,h 중 min
best = x.max(1)[0] # best_x
aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1 / thr).float().mean()
return bpr, aat
|
cs |
wh는 물체의 크기(width, height)이고, k는 anchor box이다.
예를 들어, 1by1 크기의 물체와 1by2, 3by2, 3by3 인 anchor box가 있다고 하자.
그 때의 r, x, best는 아래와 같다.
즉, best의 의미는
1. 현재 물체를 가장 잘 대변하는 하나의 anchor box의 width, height 중 (아래 그림에서는 첫 번째 box가 가장 적합함)
2. 물체의 width, height와 차이가 더 많이나는 값(아래 그림에서는 width가 더 차이가 많이남)과
3. 물체크기와의 비율을 의미한다.
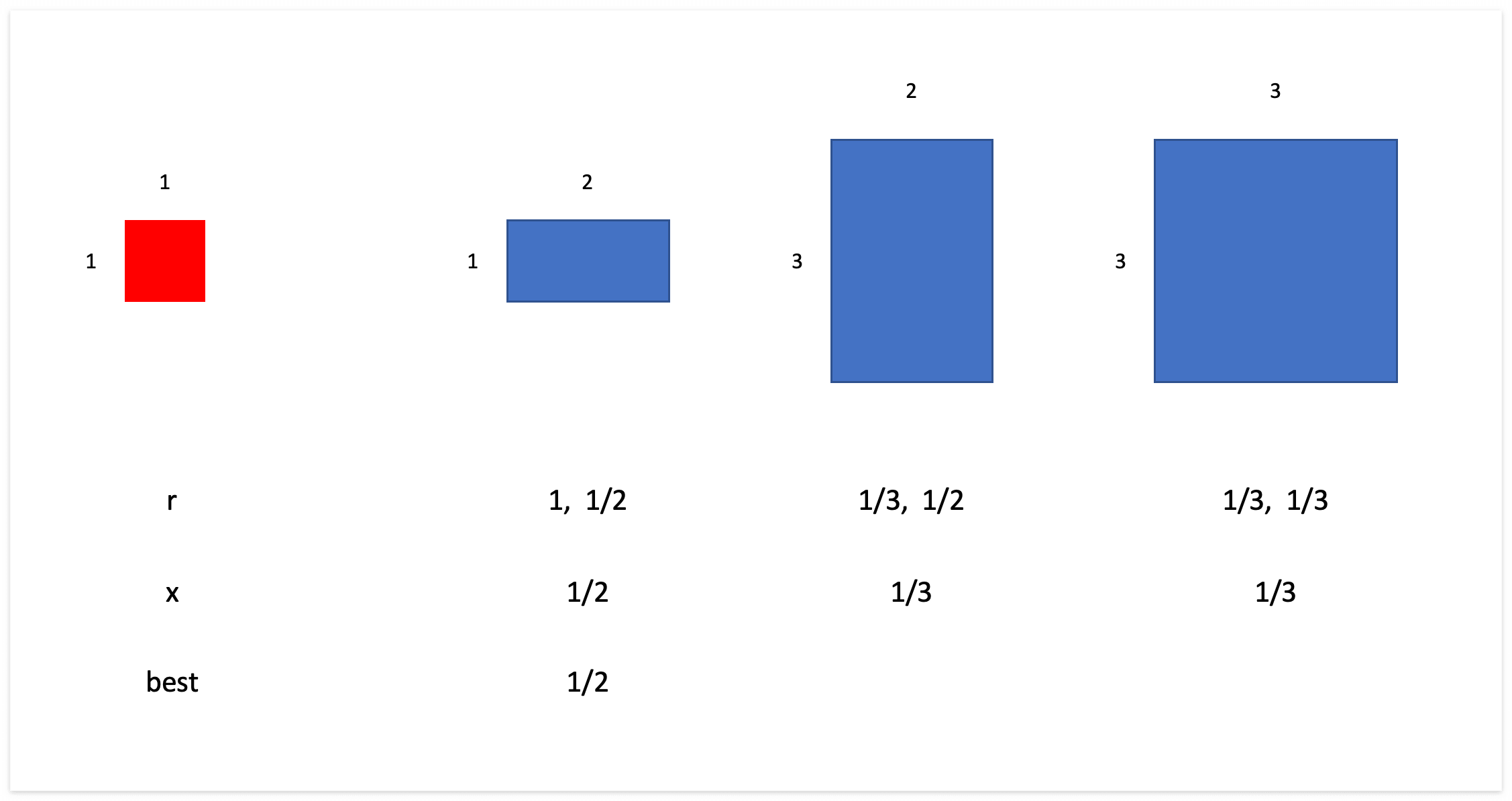
최종적으로 bpr이 best possible recall인데, best의 값이 1/thr를 넘는 물체의 비율을 계산한다.
즉, 전체 anchor box 중 물체를 가장 잘 대변하는 best anchor box일지라도 물체의 크기와 너무 차이가 많이나면 안된다는 것이다.
이렇게 계산한 현재 anchor box와 사용한 dataset의 적합도(best possible recall)은 다음과 같다.

bpr은 비율이므로 0~1 값을 가지며, 1에 가까울수록 적합하다고 할 수 있다.
코드에서는 값이 0.98을 넘으면 현재 anchor box를 그대로 사용하고, 그렇지 않으면 anchor box를 새로 정의한다.
이제 본 dataset에 맞는 새로운 anchor box를 정의한다.
전체 코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
PREFIX = colorstr('AutoAnchor: ')
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
npr = np.random
thr = 1 / thr
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k, verbose=True):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
f'past_thr={x[x > thr].mean():.3f}-mean: '
for x in k:
s += '%i,%i, ' % (round(x[0]), round(x[1]))
if verbose:
LOGGER.info(s[:-2])
return k
if isinstance(dataset, str): # *.yaml file
with open(dataset, errors='ignore') as f:
data_dict = yaml.safe_load(f) # model dict
from utils.dataloaders import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans init
try:
LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
assert n <= len(wh) # apply overdetermined constraint
s = wh.std(0) # sigmas for whitening
k = kmeans(wh / s, n, iter=30)[0] * s # points
assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
except Exception:
LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
k = print_results(k, verbose=False)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.savefig('wh.png', dpi=200)
# Evolve
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f:
f, k = fg, kg.copy()
pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k, verbose)
return print_results(k)
|
cs |
하나씩 뜯어보겠다.
참고로 Genetic Algorithm에 대한 설명은 아래 포스팅에 자세히 써놓았다.
[Optimization] 최적화 알고리즘 :: GA(Genetic Algorithm, 유전 알고리즘)란? GA 예시, R로 GA 구현하기
제조 공정에서 최적화란? 딥러닝을 공부한 사람이라면 최적화(Optimization)이라는 단어를 많이 들어보았을 것이다. 딥러닝에서 모델을 학습하는 과정에서 Cost function 값을 최소화 시키기 위한 Weight
leedakyeong.tistory.com
새롭게 필요한 k-means 라이브러리를 불러오고, 사용할 parameter들도 정의한다.
|
1
2
3
4
5
6
7
8
9
10
|
from scipy.cluster.vq import kmeans
n = 12 # 정의할 anchor box 개수
img_size = 128
thr = 2.0
gen = 1000 # GA generate 횟수
verbos = True
npr = np.random
thr = 1 / thr
|
cs |
사용할 function들도 정의한다.
metric은 위에서 best possible recall값을 뽑기위한 과정 중 x와 best를 return한다.
Genetic Algorithm에서 fitness function(anchor_fitness())에 사용하기 위함으로, GA는 이 값을 최대화 하는 방향으로 최적화한다.
best값이 thr보다 커야지만 그 값을 집계하고, 작으면 0으로 집계된다.
print_results() 는 말 그대로 결과를 print하기 위한 function으로, 결과를 sorting하는 역할을 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
# anchor box sorting
def print_results(k, verbose=True):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
f'past_thr={x[x > thr].mean():.3f}-mean: '
for x in k:
s += '%i,%i, ' % (round(x[0]), round(x[1]))
if verbose:
LOGGER.info(s[:-2])
return k
|
cs |
image를 img_size에 맞게 resize하고, 물체의 크기도 거기에 맞게 resize한다.
|
1
2
|
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
|
cs |
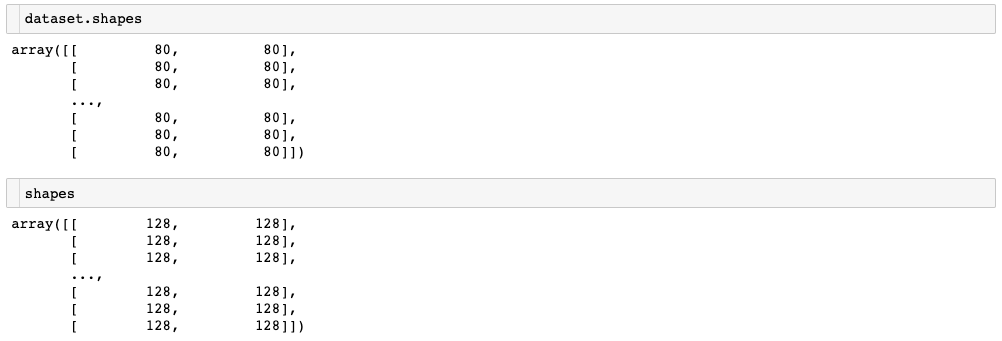
참고로 dataset.shapes와 shapes는 다음과 같다.
dataset.shape가 실제 이미지의 크기, shapes가 resize 후 이미지의 크기이다.
만약, 너무 작은 물체가 있다면 outlier로 간주하여 제외한다.
너무 작다의 기준은 "물체의 width, height 중 하나라도 3보다 작으면" 이다.
|
1
2
3
4
5
|
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
|
cs |
이제 k-means를 실행해서 GA 실행 전 초기 anchor box를 정의한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# Kmeans init
try:
LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
assert n <= len(wh) # apply overdetermined constraint
s = wh.std(0) # sigmas for whitening
k = kmeans(wh / s, n, iter=30)[0] * s # points
assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
except Exception:
LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
k = print_results(k, verbose=False)
|
cs |
만약, 전체 물체의 개수가 정의하고자 하는 anchor의 개수보다 작다면 k-means를 실행하지 않고 random한 값으로 배정한다.
이제 Gentic Algorithm으로 더 좋은 Anchor box를 찾는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# Evolve
verbose = False
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f:
f, k = fg, kg.copy()
pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k, verbose)
# return print_results(k)
|
cs |
verbose는 GA 과정을 보고싶다면 True, 결과만 보고싶다면 False로 설정한다.
k-means로 정의한 초기 anchor box가 얼마나 적합한지 anchor_fitness()로 계산하고,
parameter 로 전달한 gen 횟수만큼 변형, 선택의 GA 과정을 반복한다.
kg가 k에 변형을 일으킨 값이고, fg는 변형을 일으킨 kg로 다시 anchor_fitness()를 계산한 값이다.
기존보다 변형을 일으킨 anchor box가 더 적합하다면 대체하고, 그렇지않으면 유지한다.
이렇게 gen 만큼 반복하면 완성이다.
처음 anchor box에 비해 얼마나 좋아졌는지 best possible recall 값을 다시 계산해보면 다음과 같다.

더욱 1에 가까워진것을 볼 수 있다.
이제 4개의 각 Scale에 맞게 정렬해준다.

마지막으로, 이 값을 반올림해서 정수로 만들어주면 완성이다.
|
1
|
m.anchors = np.round(m.anchors)
|
cs |
'AI > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLO v5, v6 Loss (3) | 2022.08.10 |
|---|---|
| [Object Detection] YOLOv5, YOLOv6 Loss 구하는 과정 중 build_targets() 이해하기 (2) | 2022.08.04 |
| [Object Detection] YOLO v1 ~ v6 비교(2) (8) | 2022.06.23 |
| [Object Detection] YOLO v1 ~ v6 비교(1) (6) | 2022.06.23 |
| [Python] Object Detection Mosaic Augmentation :: YOLO v5 (2) | 2022.06.09 |