Object Detection이란?
Object Detection은 말 그대로 물체를 검출하는 문제이다.
딥러닝으로 이미지 관련 무언가를 한다면 대체로 다음과 같다.

1. Classification
가장 기본이 되는 문제이다.
이미지가 주어졌을 때, Object가 한 개 있고, 그 물체가 무엇인지 맞추는 문제이다.
이 Classification을 위해 유명한 데이터셋들이 있는데,
CAT/DOG, MNIST(0~9의 숫자를 손글씨로 써놓은 이미지) 등 간단한 데이터셋도 있고,
ImageNet과 같이 1,000만개가 넘고 1,000개의 Class를 가지고있는 데이터셋도 있다.
Classification에 사용되는 CNN 아키텍쳐들이 Object Detection이나 Segmentation에 Backborn으로 사용된다.
2. Classifation + Localization
이미지에 한 개의 Object가 있을 때, 그 Object의 위치를 찾고, 무엇인지까지 맞추는 문제이다.
3. Object Detection
이미지에 한 개 이상의 Object가 있을 때, 각각의 Object에 대해 위치와 무엇인지까지 맞추는 문제이다.
4. Instance Segmentaion
이미지에 한 개 이상의 Object가 있을 때, 각각의 Object에 픽셀단위 위치와 무엇인지까지 맞추는 문제이다.
Object Detection은 Box 형태의 위치를 찾고, Segementation은 픽셀단위의 위치를 찾는다는 차이가 있다.
이들 중에서 Object Detection에 대해 자세히 알아보겠다.
어떤 알고리즘들이 발전했고, 어떻게 하는지에 대해 알아보기 앞서, 용어들을 먼저 정리하고 가겠다.
Object Detection 주요 용어 정리
1. Bounding Box
bounding box란 아래 이미지처럼 하나의 객체 전체를 포함하는 가장 작은 직사각형을 의미한다.
아래 이미지에는 총 10개의 Bounding Box가 있다.
Object Detection 문제는 크게 ①물체의 위치를 찾는 문제와 ②그 물체가 무엇인지를 구분하는 문제가 있는데, 이 중 물체의 위치를 찾을 때 이 Bounding Box의 형태로 찾는다.
값은 (xmin, ymin, xmax, ymax) 혹은 (x_center, y_center, w, h)의 형태로 저장한다.
x_center, y_center는 박스의 중심점을 의미하며, w는 width, h는 height를 의미한다.
실제 Label이 되는 값은 Ground Truth라고 부른다.
2. IoU(Intersection Over Union)
실제값(Ground Truth)와 모델이 예측한 값이 얼마나 겹치는지를 나타내는 지표이다.
실제 box와 예측한 box의 교집합/합집합을 의미한다.
이 값이 클 수록 잘 예측했다고 판단할 수 있다.
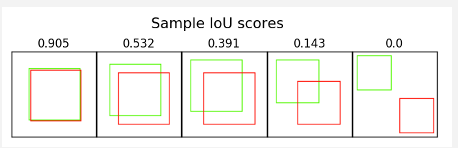
예를 들어, 두 이미지가 거의 겹친다면 맨 왼쪽 이미지처럼 IoU값이 클 것이고,
두 이미지가 아예 겹치지 않는다면 맨 오른쪽 이미지처럼 IoU값은 0이된다.
3. Confidence Score
Confidence Score란 Object Detection 알고리즘마다 조금씩 차이는 있지만, 보편적으로 찾은 Bounding Box안에 물체가 있을 확률을 의미한다.
아래 이미지에서 노란색 Box에는 물체가 없으므로 Confidence Score는 0이고, 빨간색 Box는 물체가 있으므로 1이된다.

이 값은 단순하게 물체가 있을 확률로 계산되기도 하고,
물체가 있을 확률 * IoU로 계산되기도 하고,
정확히 어떤 물체의 Class일 확률 * IoU가 되기도 한다.
각 알고리즘마다 조금씩 차이는 있으나, 의미는 비슷하다.
4. NMS(Non-Maximum Suppression)
NMS를 수행하는 이유는 동일한 물체를 가리키는 여러 박스의 중복을 제거하기 위함이다.
Object Detection모델은 대체로 아래 왼쪽 이미지처럼 실제 물체 개수보다 훨씬 많은 Bounding Box를 예측한다.
NMS는 이를 오른쪽 이미지처럼 각 물체별 가장 좋은 Box 한 개만 남기고 나머지는 다 지우는 역할을 한다.

그 방법은 Confidence Score와 IoU를 이용하는데,
① 특정 Confidence Score 이하의 Bounding Box는 제거한다. (Confidence Score Threshold는 HyperParameter)
② 남은 Bounding Box들을 Confidence Score 기준으로 내림차순 정렬한다.
③ 맨 앞 박스부터 기준으로, 이 박스와 IoU가 특정 Threshold 이상인 박스들은 모두 제거한다. (IoU Threshold도 HyperParameter)
그리고 ②와 ③을 반복한다.
쉽게 2중 for 문을 생각하면되고, IoU가 일정 이상이면 두 박스는 서로 같은 물체를 가리키는 것이라고 판단하여 상대적으로 Confidence Score가 낮은 박스를 제거하는 것이다.
Confidence Threshold가 높을수록, IoU Threshold가 낮을수록 더 많은 박스가 제거된다.
예를 들어, Object Detection 모델이 다음과 같은 Bounding Box들을 예측했다고 해보자. (Confidence Threshold보다 낮은 Box는 이미 제거된 상태)
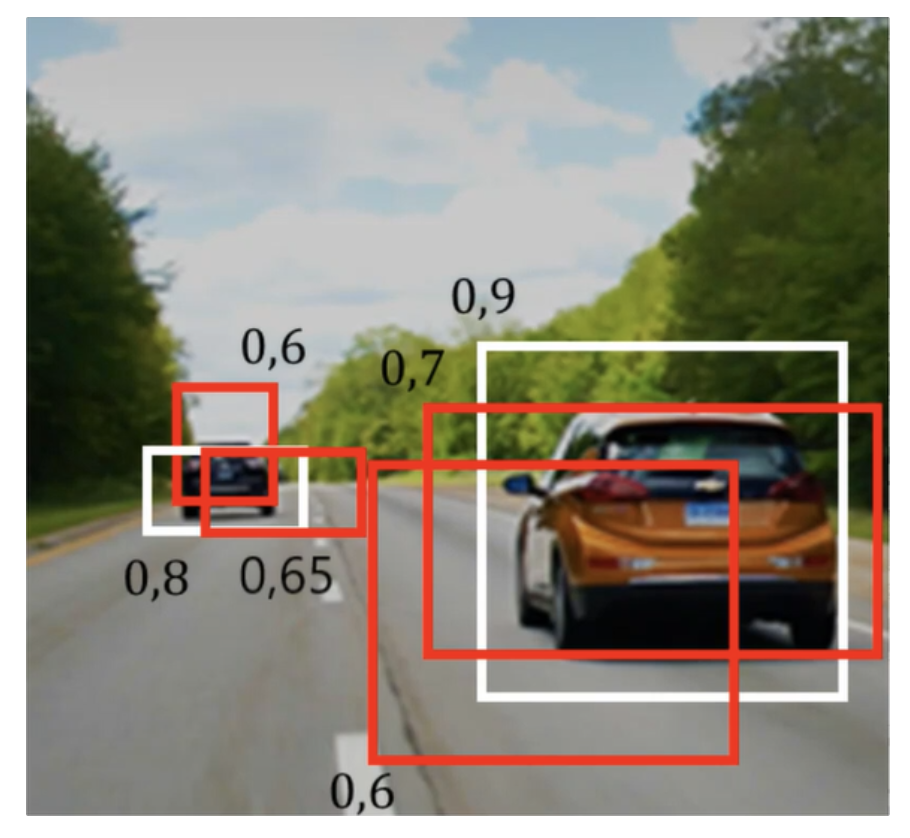
검정 숫자가 Confidence Score이다.
이 Score를 기준으로 Box들을 내림차순 정렬하면 [0.9 박스, 0.8 박스, 0.7 박스, 0.65 박스, 0.6 박스, 0.6 박스]가 된다.
먼저, 0.9 박스를 기준으로
0.8 박스와는 겹치지 않으므로 0.8 박스는 stay
0.7 박스와는 일정 이상 겹치므로 0.9 박스와 같은 물체를 가리킨다 판단, 삭제
0.65, 0.6(왼쪽) Box는 IoU가 0이므로 stay
0.6(오른쪽) Box는 IoU가 일정 이상 겹치므로 삭제
-> [0.9, 0.8, 0.65, 0.6]
이제 0.8 박스를 기준으로
...
이렇게 하면 최종적으로 흰색 Box가 남고 빨간색 Box들은 삭제된다.
5. AP(Average Precision) and mAP(mean Average Precision) :: 성능평가지표
AP와 mAP가 무엇인지에 앞서, Precision(정밀도)와 Recall(재현율)이 무엇이지 먼저 알아야한다.
정밀도와 재현율은 Classification문제에서 주로 사용하는 성능평가 지표이다.
아래 표를 먼저 설명하겠다.
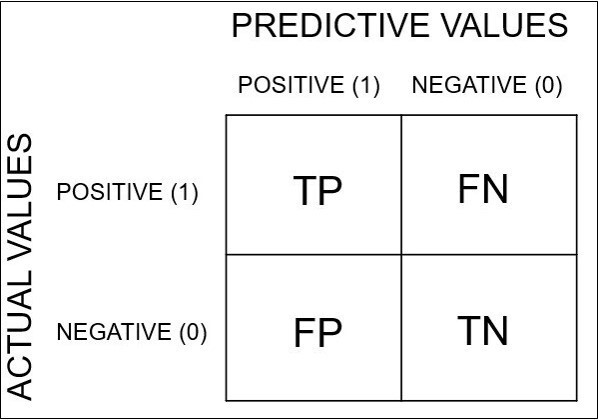
T는 True, F는 False, P는 Positive, N은 Negative를 의미한다.
T일때는 예측과 실제값이 동일한 경우, F일 때는 예측값과 실제값이 상이한 경우이다.
TP는 모델이 맞다고 예측했는데 실제로 맞은 경우이다.
Object Detection 문제에서는 Ground Truth와 Predicted Bounding Box의 IoU가 일정 threshold이상이고, 같은 Class를 잘 예측했을 때 TP라 판단한다.
즉, 실제 물체가 있는 위치와 Class를 모델이 잘 찾은 경우이다.
FP는 모델이 맞다고 예측했는데 실제로는 틀린 경우이다.
Object Detetion에서는 모델은 물체가 있다고 검출했지만, 실제로는 물체가 없는 경우이다.
즉, 잘못 검출한 경우이다.
FN은 모델은 틀리다고 예측했는데 실제로는 맞는 경우이다.
실제 존재하는 물체를 아예 Detect하지 못한 경우이다.
TN은 모델도 틀리다고 예측했고, 실제로도 틀린 경우이다.
즉, 실제로 그 자리에 물체가 없었고 모델도 그 자리에 Bounding Box를 예측하지 않은 경우이다.
이를 정리하면 다음과 같다.
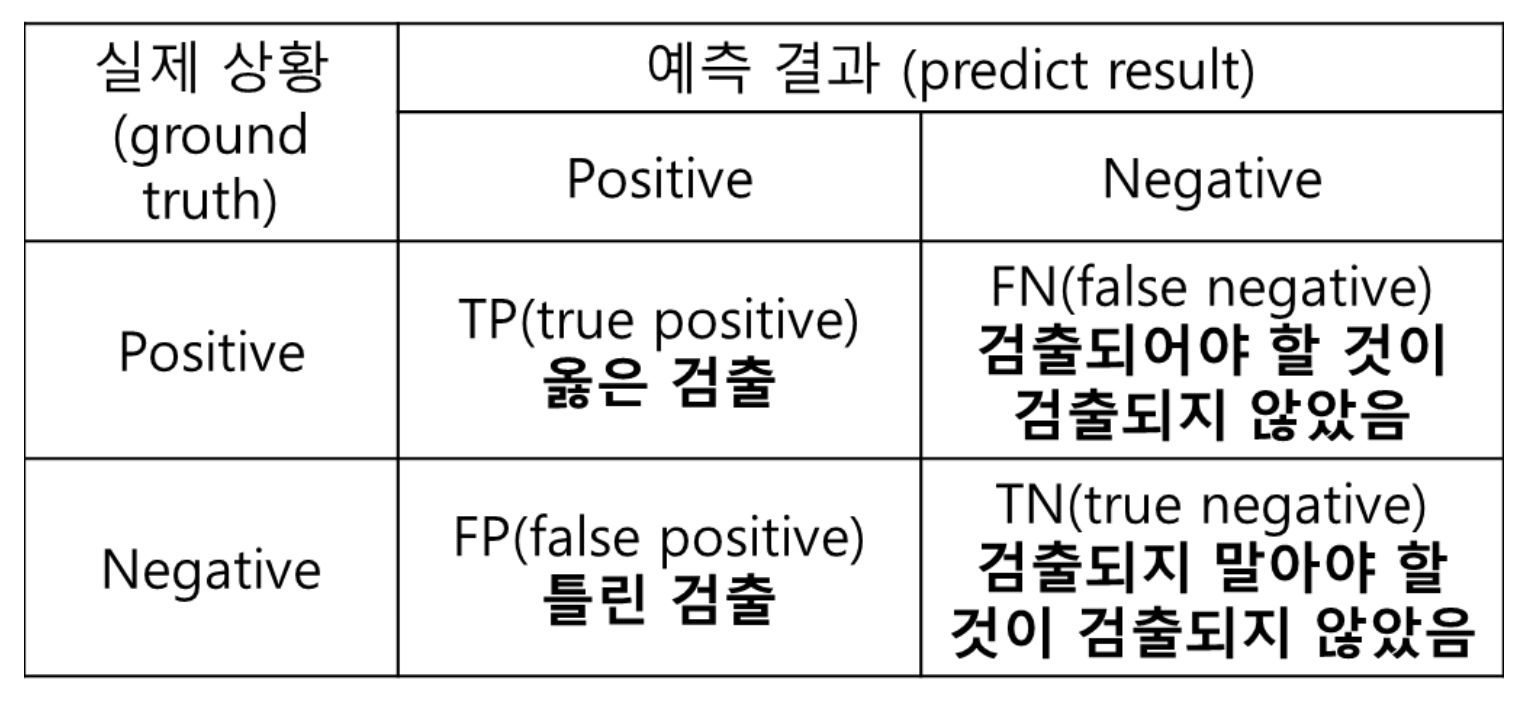
그래서 정밀도(Precision)는 모든 검출 결과 중 옳게 검출한 비율이다.
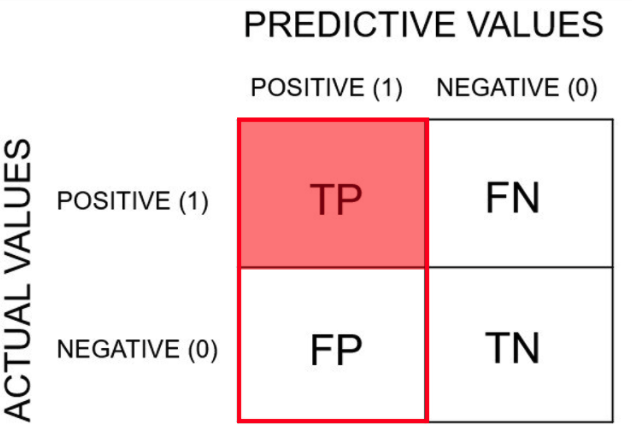
즉, 정밀도를 식으로 나타내면 다음과 같다.
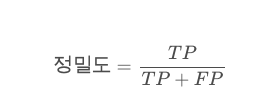
재현율(Recall)은 검출해내야 하는 물체들 중 제대로 검출된 비율이다.
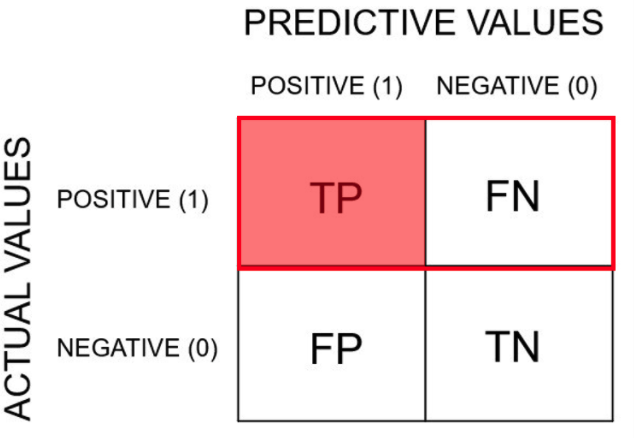
이를 식으로 나타내면 다음과 같다.
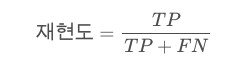
모델의 성능이 좋으려면 이 두 값 모두 높아야 할 것이다.
일반적으로 Precision과 Recall은 살짝 반비례관계가 있다.
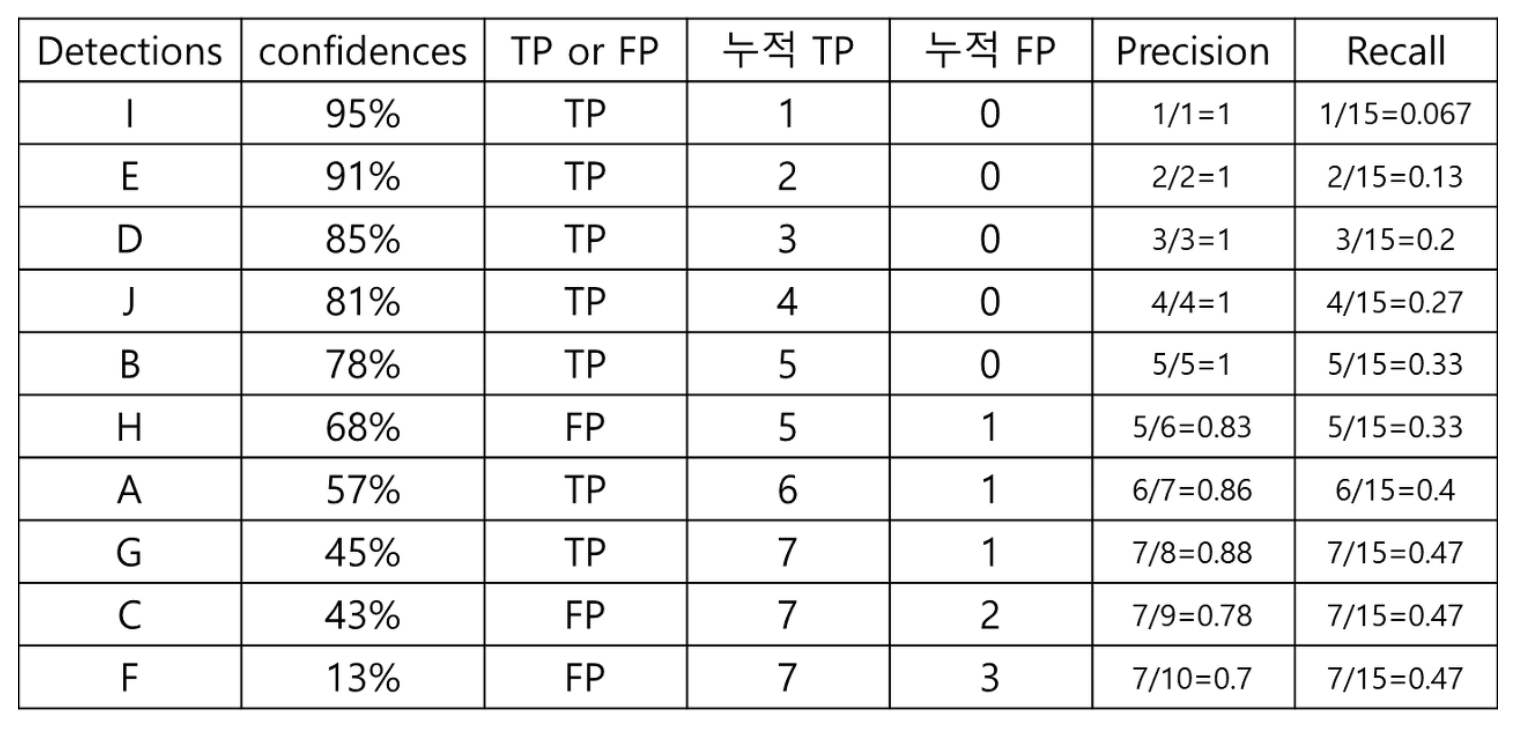
예를 들어, 총 15개의 Object가 검출되어야 하는 이미지에서 아래 표와 같이 모델이 10개의 객체 만 검출했고, 그 때의 confidence와 TP/FP 여부가 있다고 하자.
TP는 7개, FP는 3개이다.
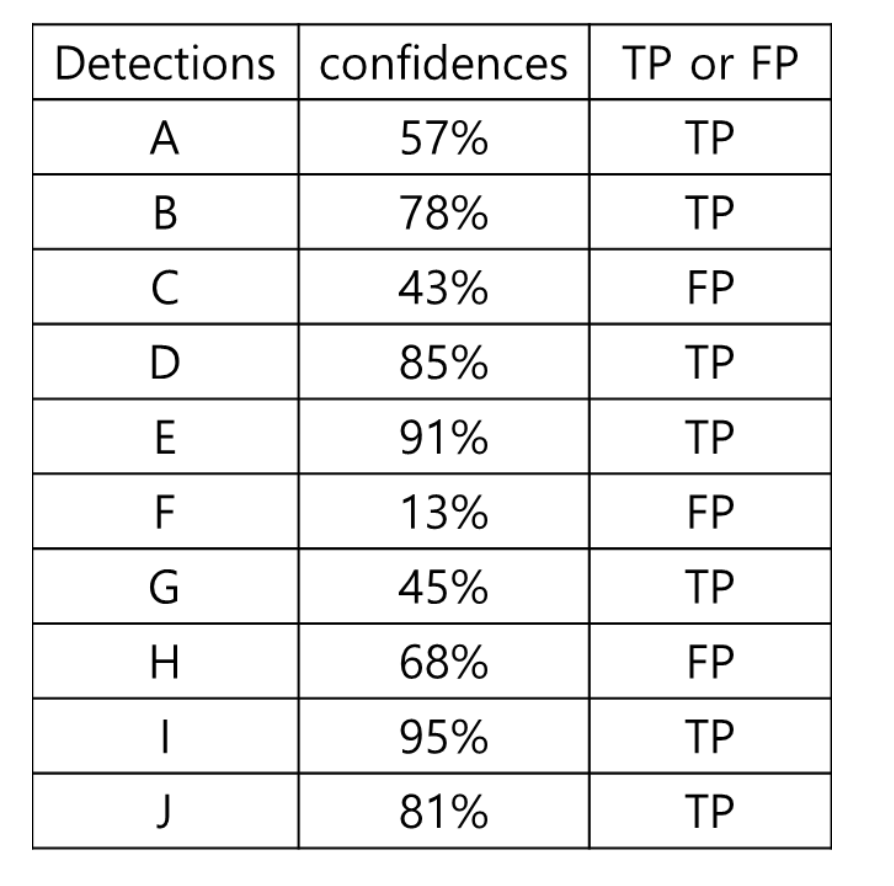
Confidence의 threshold를 0으로 했을 때 즉, 10개 모두 검출(Positive)했다고 판단했을 때 TP, FP, FN을 표로 나타내면 다음과 같다.

Precision = 옳게 검출된 Object 개수 / 총 검출된 Object 개수 = 7/10 = 0.7 이고,
Recall = 옳게 검출된 Object 개수 / 검출되어야 하는 Object 개수 = 7/15 = 0.47 이다.
반대로, Confidence threshold를 아주 엄격하게 적용하여 95%이상일 때만 검출(Positive)했다고 판단한다면,
검출된 물체는 단 1개이고,
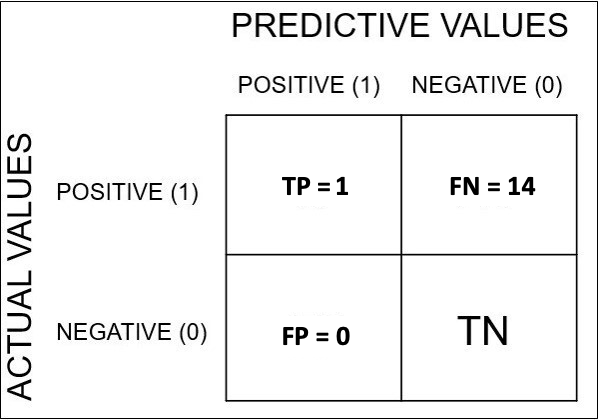
Precision = 1/1 = 1
Recall = 1/15 = 0.067이 된다.
Confidence Threshold에 따른 Precision과 Recall을 정리하면 다음과 같다.
이를 x축에 Recall, y축에 Precision으로 그래프를 그리면 다음과 같다.
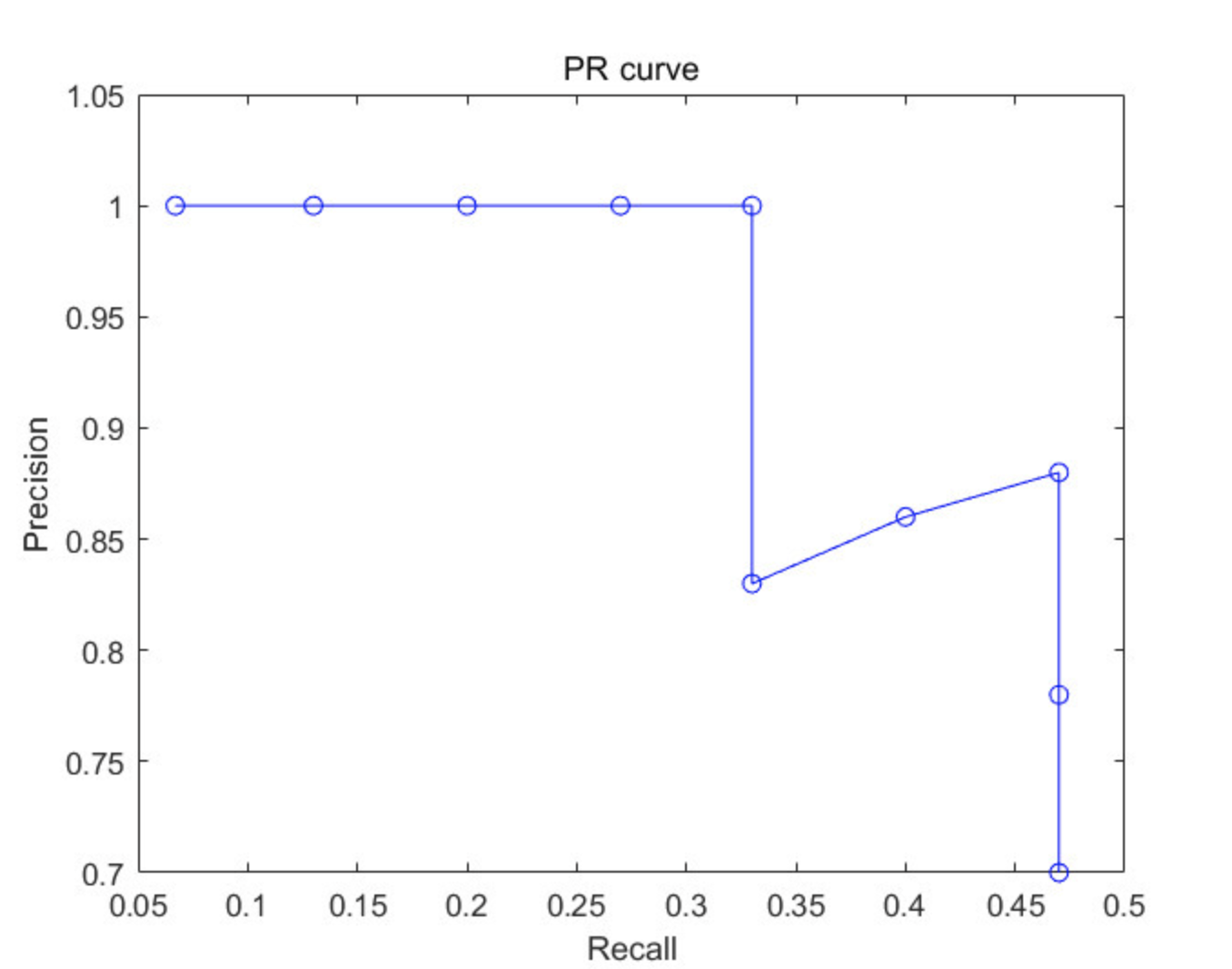
이 때, 저 그래프의 파란 선 아래 면적을 AP(Average Precision)이라 한다.
AP의 의미는 Recall을 0부터 1까지 0.1씩 바꿔가면서 그 때의 Precision을 계산하고, 그들을 평균낸 값이다.
Precision과 Recall이 모두 커야 모델의 판단력이 좋은 것이므로, 이 값은 클 수록 잘 예측했다고 판단한다.
Classification 문제에서 RoC Curve 아래 면적이 클 수록 잘 예측했다고 판단하는 것과 비슷하다.
mAP(mean AP)는 각 Class마다 AP를 계산하고 그들을 평균낸 값이다.
6. Dataset
마지막으로 Object Detection에 주로 사용하는 Dataset들을 소개하겠다.
6-1. Pascal VOC Data
대표적인 Object Detection을 위한 데이터셋으로, 2007년 버전과 2012년 버전이 있다.
총 20개의 Class가 있으며, 데이터는 https://pjreddie.com/projects/pascal-voc-dataset-mirror/ 에서 다운받을 수 있다.
PASCAL_CLASSES = [
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"pottedplant",
"sheep",
"sofa",
"train",
"tvmonitor"
]
파일을 다운받으면 다음과 같은 구조로 되어있다.

Annotations : 각 image별 Label xml 파일. (class, 이미지 size, Bounding box에 대한 정보 등)

ImageSets : 특정 클래스가 어떤 이미지에 있는 지 등에 대한 정보를 포함하는 폴더(test, train, val, ...)
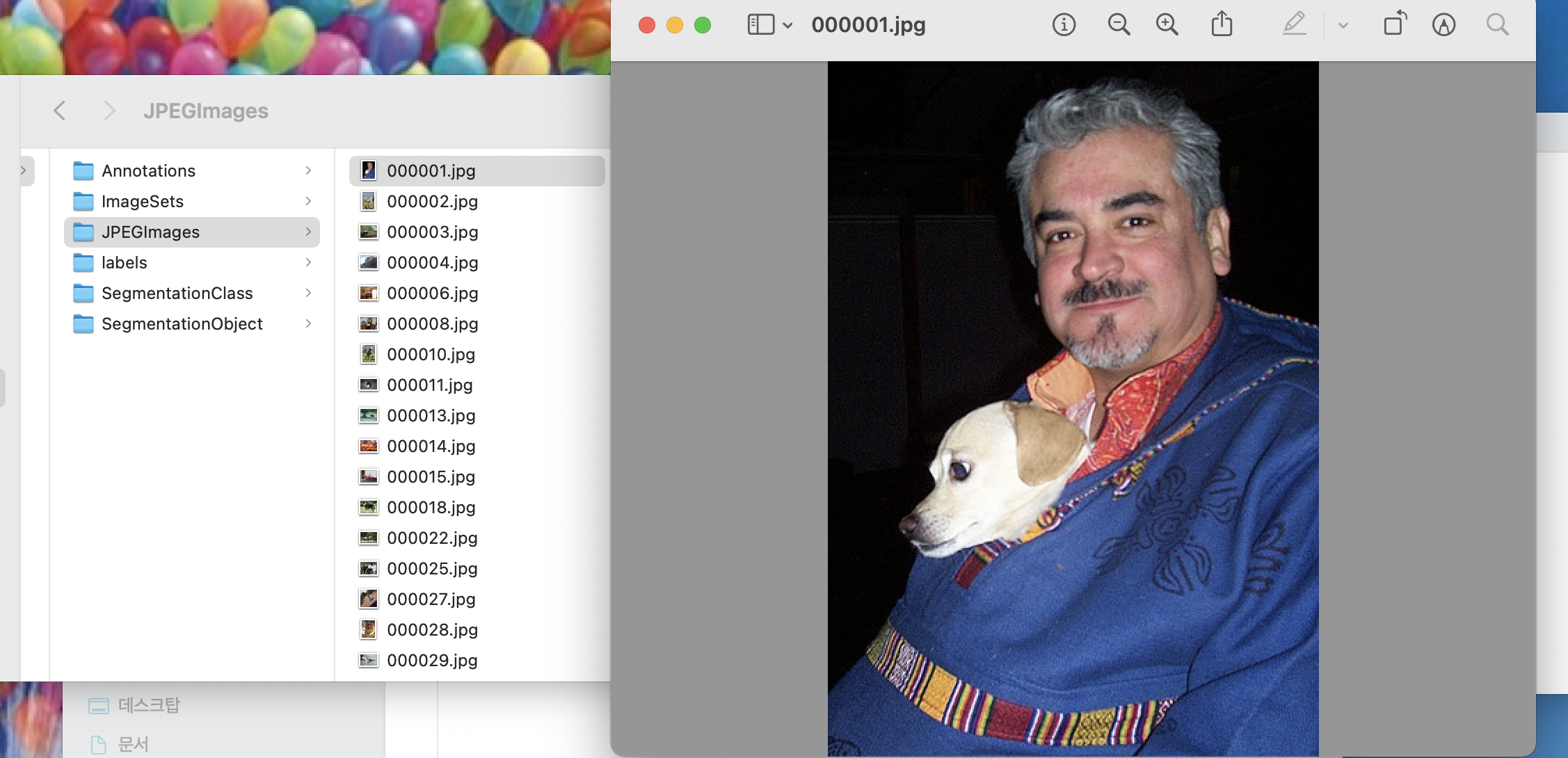
JPEGImages : jpg 이미지를 저장하는 폴더
SegmentationClass, SegmentationObject : Semantic, Instance Segmentaion을 학습하기 위한 label 이미지들
6-2. COCO Dataset
200,000개의 이미지, 80개의 Class를 포함한 데이터셋이다.
https://cocodataset.org/#home 에서 다운받을 수 있다.
COCO_LABELS = ['person',
'bicycle',
'car',
'motorcycle',
'airplane',
'bus',
'train',
'truck',
'boat',
'traffic light',
'fire hydrant',
'stop sign',
'parking meter',
'bench',
'bird',
'cat',
'dog',
'horse',
'sheep',
'cow',
'elephant',
'bear',
'zebra',
'giraffe',
'backpack',
'umbrella',
'handbag',
'tie',
'suitcase',
'frisbee',
'skis',
'snowboard',
'sports ball',
'kite',
'baseball bat',
'baseball glove',
'skateboard',
'surfboard',
'tennis racket',
'bottle',
'wine glass',
'cup',
'fork',
'knife',
'spoon',
'bowl',
'banana',
'apple',
'sandwich',
'orange',
'broccoli',
'carrot',
'hot dog',
'pizza',
'donut',
'cake',
'chair',
'couch',
'potted plant',
'bed',
'dining table',
'toilet',
'tv',
'laptop',
'mouse',
'remote',
'keyboard',
'cell phone',
'microwave',
'oven',
'toaster',
'sink',
'refrigerator',
'book',
'clock',
'vase',
'scissors',
'teddy bear',
'hair drier',
'toothbrush'
]
참고
NMS : https://driip.me/34deae03-7a40-44ee-849d-756e6e852f49
AP & mAP : https://lapina.tistory.com/98
'AI > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLO v1 ~ v6 비교(1) (6) | 2022.06.23 |
|---|---|
| [Python] Object Detection Mosaic Augmentation :: YOLO v5 (2) | 2022.06.09 |
| [Python] mAP(mean Average Precision) 예시 및 코드 (1) | 2022.06.08 |
| [Python] albumentations 라이브러리를 이용한 Image Agumentation :: Bounding Box 좌표와 함께 이미지 변형하는 방법 (0) | 2022.05.06 |
| [Object Detection(객체 검출)] YOLO v1 : You Only Look Once (8) | 2022.04.04 |