앞 서, 시계열 데이터와 시계열 분석에 대한 간단한 설명과 시계열 분해법에 대해 설명했다.
시계열 분해란?(Time Series Decomposition) :: 시계열 분석이란? 시계열 데이터란? 추세(Trend), 순환(Cycle),
시계열 데이터란? 시간에 순차적으로 관측한 값들의 집합이며, 예측 모델에서 시간을 변수로 사용하는 특징이 있다. 시계열 데이터 분석이란? 과거 데이터의 패턴을 분석하여 미래의 값을 예측
leedakyeong.tistory.com
이번 포스팅에서는 시계열 데이터 분석 기법 중 가장 기본이 되는 ARIMA 모형에 대해 설명하겠다.
ARIMA란?
Autoregressive Integrated Moving Average 라는 뜻으로, AR(Autoregression) 모형과 MA(Moving Average) 모형을 합친 모형이다.
AR과 MA 모형에 대해 설명하기 전에, ARIMA 모형은 시계열 데이터의 정상성(Stationary)를 가정하고 있는데,
정상성이란?
평균, 분산이 시간에 따라 일정한 성질이다. 즉, 시계열 데이터의 특성이 시간의 흐름에 따라 변하지 않음을 의미한다.
예로, 추세나 계절성이 있는 시계열은 정상 시계열이 아니다.
이렇듯 정상성을 나타내지 않는 데이터는 복잡한 패턴을 모델링하여 분석하기 어렵기 때문에, 정상성을 갖도록 로그 변환, 차분 등 전처리 후 분석을 시행한다.
정상 시계열 변환
정상성을 나타내지 않는 데이터를 정상 시계열로 변환하는 방법은 다음과 같다.
1. 변동폭이 일정하지 않은 경우 -> 로그 변환
2. 추세, 계절성이 존재하는 경우 -> 차분(differencing, \(y_t-y_{t-1}\))
단, 1차 차분으로 정상성을 띄지 않으면, 차분을 반복한다.

예로 위 (a)와 같이 시간에 따라 변동폭이 일정하지 않고, 추세와 계절적 영향이 존재하는 비정상 시계열이 존재한다.
로그 변환을 하면 (b)와 같이 변동폭이 일정해지고, 차분을 하면 (c)와 같이 평균이 일정한 시계열로 변환된다.
즉, 로그 변환과 차분을 함께하여 (d)와 같이 평균과 분산이 일정한 정상 시계열로 변환할 수 있다.
AR 모형이란?
자귀 회귀 모형으로, Auto Correlation의 약자이다.
자기상관성을 시계열 모형으로 구성하였으며, 예측하고자 하는 특정 변수의 과거 관측값의 선형결합으로 해당 변수의 미래값을 예측하는 모형이다.
이전 자신의 관측값이 이후 자신의 관측값에 영향을 준다는 아이디어에 기반하였다.
AR(p) 모형의 식은 다음과 같다.
$$ y_t=c+\phi_1y_{t-1}+\phi_2y_{t-2}+...+\phi_py_{t-p}+\varepsilon_t $$
\(y_t\)는 \(t\)시점의 관측값, \(c\)는 상수, \(\phi\)는 가중치, \(\varepsilon_t\)는 오차항을 의미한다.
MA 모형이란?
Moving Average 모형으로, 예측 오차를 이용하여 미래를 예측하는 모형이다.
MA(q) 모형의 식은 다음과 같다.
$$ y_t=c+\theta_1\varepsilon_{t-1}+\theta_2\varepsilon_{t-2}+...+\theta_q\varepsilon_{t-q}+\varepsilon_t $$
ARIMA 모형이란?
ARIMA(p,d,q) 모형은 d차 차분한 데이터에 위 AR(p) 모형과 MA(q) 모형을 합친 모형으로, 식은 다음과 같다.
$$ y^{'}_t=c+\phi_1y^{'}_{t-1}+\phi_2y^{'}_{t-2}+...+\phi_py^{'}_{t-p}+\theta_1\varepsilon_{t-1}+\theta_2\varepsilon_{t-2}+...+\theta_q\varepsilon_{t-q}+\varepsilon_t $$
단, \(y^{'}\)은 d차 차분을 구한 시계열, \(p\)는 자기회귀 부분의 차수, \(d\)는 차분 회수, \(q\)는 이동평균 부분의 차수이다.
AR(p)모형과 ARIMA(p,0,0)모형은 같은 모형이며, MA(q)모형과 ARIMA(0,0,q) 모형은 같은 모형이다.
p와 q는 ACF 그래프와 PACF 그래프를 그려서 확인한다.
ACF(자기상관함수, AutoCorrelation Function)란?
시차에 따른 일련의 자기상관을 의미하며, 시차가 커질수록 ACF는 0에 가까워진다.
정상 시계열은 상대적으로 빠르게 0에 수렴하며, 비정상 시계열은 천천히 감소하고, 종종 큰 양의 값을 가진다.
이 때, ACF를 구하는 식은 일반 Correlation 구하는 식과 동일하다.
다음은 \(y_t\)와 \(y_{t+k}\)사이의 자기상관을 구하는 식이다.
$$ ACF(k)=\frac{\sum_{t=1}^{N-k}(y_t-\bar{y})(y_{t+k}-\bar{y})}{\sum_{t=1}^N(y_t-\bar{y})^2} $$
ACF는 정상성을 판단하는데 유용하다.
예로 다음은 200일 동안의 구글 주식 가격에 대한 그래프이다.
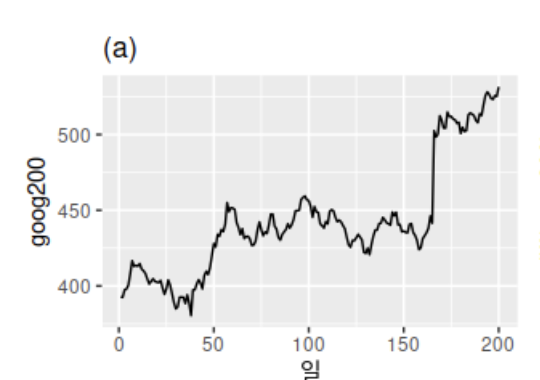
점진적으로 증가하는 분명한 추세가 있기 때문에 정상성을 띄지 않는다.
이를 ACF 그래프로 그려보면 다음과 같다.
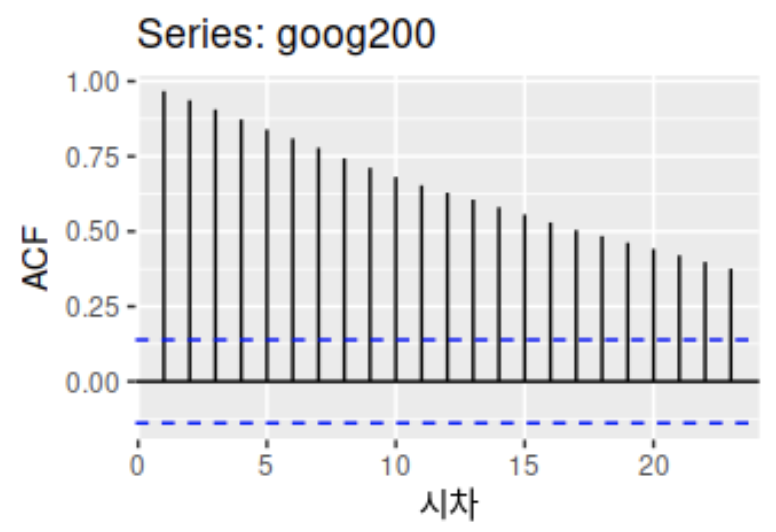
ACF가 아주 느리게 감소하는 것을 볼 수 있다.
차분을 하여 정상 시계열로 변환한 뒤 ACF를 그려보면 다음과 같다.
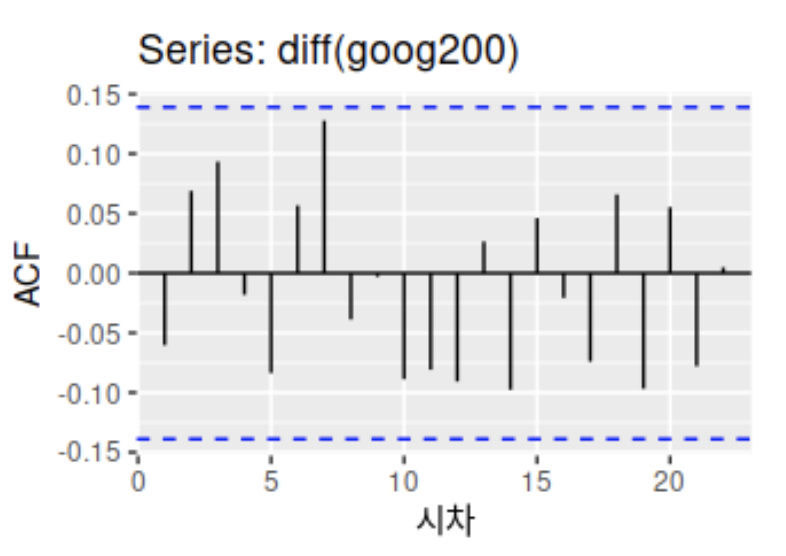
그래프의 y축을 보면 차분 전 ACF 그래프에 비해 값 자체가 훨씬 0에 가까우며, 비교적 빠르게 0에 수렴하는 것을 볼 수 있다.
PACF(편자기상관함수, Partial AutoCorrelation Function)란?
시차에 따른 일련의 편자기상관이며, 시차가 다른 두 시계열 데이터 간의 순수한 상호 연관성이다.
즉, \(y_t\)와 \(y_{t-k}\)간의 순수한 상관관계로서 두 시점 사이에 포함된 모든 \(y_{t-1}, y_{t-2}, ..., y_{t-k+1}\)의 영향은 제거된다.
\(y_t\)와 \(y_{t+k}\)사이의 편자기상관을 구하는 식은 다음과 같다.
$$ PACF(k)=Corr(e_t, e_{t-k}) $$
단,
$$ e_t = y_t-(\beta_1y_{t-1} + ... + \beta_{k-1}y_{t-(k-1)}) $$
즉, ACF와 PACF를 동시에 고려하여 ARIMA 모델의 p와 q를 결정하는데 그 방법은 다음과 같다.

예로 다음과 같은 ACF와 PACF가 그려졌다고 하자.

ACF는 시차1 이후에 0에 가까워지고, PACF는 시차2 이후에 0에 수렴했다.
ACF와 PACF 모두 점진적으로 0에 이르고 있다.
따라서 AR(2), MA(1), ARIMA(2,1) 등의 모델을 활용할 수 있다.
모델링을 마친 후 잔차의 ACF 그래프를 그려, 정상성을 따르는지 확인해야 한다. 만약, 정상성을 따르지 않는다면, p,d,q의 파라미터를 재조정하여 다시 모델링하는 작업을 진행해야 한다.
'AI > 시계열자료 분석' 카테고리의 다른 글
| Deep Learning for Time Series Forecasting (kaggle 코드 리뷰) (30) | 2021.05.27 |
|---|---|
| [Python] 날씨 시계열 데이터(Kaggle)로 ARIMA 적용하기 (16) | 2021.05.25 |
| 시계열 분해란?(Time Series Decomposition) :: 시계열 분석이란? 시계열 데이터란? 추세(Trend), 순환(Cycle), 계절성(Seasonal), 불규칙 요소(Random, Residual) (0) | 2021.05.24 |
| [시계열 자료 분석] R에서 AirPassengers 데이터 선형계절추세모형 적합시키기 (0) | 2019.10.31 |
| [R] stl() 이란? :: stl parameter :: stl s.window (0) | 2019.10.29 |