2020/04/21 - [통계 지식/Algorithm] - Decision Tree란? :: ID3 알고리즘, 엔트로피란?
Decision Tree란? :: ID3 알고리즘, 엔트로피란?
의사결정나무란? Decision Tree란? 의사결정 규칙을 나무구조로 나타내에 전체 데이터를 소집단으로 분류하거나 예측하는 분석기법 전체 데이터에서 마치 스무고개하듯이 질문하며 분류해나간다. 그 모양이 마치..
leedakyeong.tistory.com
2020/04/21 - [통계 지식/Algorithm] - 의사결정나무(Decision Tree) :: CART 알고리즘, 지니계수(Gini Index)란?
의사결정나무(Decision Tree) :: CART 알고리즘, 지니계수(Gini Index)란?
이전 포스팅에서 의사결정나무란 무엇인지, 어떤 기준으로 모델을 만들어가며 불순도가 무엇인지와 ID3 알고리즘에 대해 소개했다. 지난 포스팅 바로가기 https://leedakyeong.tistory.com/entry/Decision-Tree%EB..
leedakyeong.tistory.com
2020/04/21 - [통계 지식/Algorithm] - 의사결정나무(Decision Tree) :: 독립변수가 연속형 일 때
의사결정나무(Decision Tree) :: 독립변수가 연속형 일 때
2020/04/21 - [통계 지식/Algorithm] - Decision Tree란? :: ID3 알고리즘, 엔트로피란? Decision Tree란? :: ID3 알고리즘, 엔트로피란? 의사결정나무란? Decision Tree란? 의사결정 규칙을 나무구조로 나타내에..
leedakyeong.tistory.com
이전 포스팅에서 의사결정 나무의 개념과, 가장 대표적인 두 알고리즘 ID3, CART 에 대해 알아보았다.
그런데, 위 포스팅들에서 들었던 예시대로 tree의 모든 terminal node를 순도 100% 인 상태로 만들면, 분기가 너무 많아 과적합(overfitting)이 발생한다.
과적합이란? 학습데이터에 대해 과하게 학습하여 실제 데이터에 대한 오차가 증가하는 현상
이를 예방하기 위해 여러가지 방법이 있지만, Decision Tree에 특화된 가지치기와 앙상블 기법을 소개하고자 한다.
가지치기(Pruning)란?
모든 terminal node의 순도가 100% (불순도가 0) 인 상태를 Full Tree라 한다.
이 경우 분기가 너무 많아 과적합의 위험이 발생한다.
이를 방지하기 위해 적절한 수준에서 terminal node를 결합해주는 것을 가지치라 한다.
가지치기란? 의사결정나무에서 과적합을 방지하기 위해 적절한 수준에서 terminal node를 결합해 주는 것
가지치기의 종류에는 사전 가지치기와 사후 가지치기가 있다.
사전 가지치기는 트리의 최대 depth, 각 노드에 있어야 할 최소 관측값 수 등을 미리 지정하여 트리를 만드는 도중에 stop 하는 것이며,
사후 가지치기는 트리를 먼저 Full Tree로 만든 후 적절한 수준에서 terminal node를 결합해 주는 것이다.
앞 서 소개했던 CART 알고리즘에서 사후 가지치기로 Cost-Complexity 라는 개념이 나오는데, 식은 다음과 같다.
$$ CC(T)=Err(T)+\alpha*L(T) $$
CC(T) : Tree의 비용 복잡도
Err(T) : 오분류율(불순도)
L(T) : terminal node의 수 (= 구조 복잡도)
Alpha : Err(T)와 L(T)를 결합하는 가중치 (= Complexity Parameter)
여기서 Alpha는 CP(Complecity Parameter)라고도 하는데, 이 값으로 트리의 복잡도를 조정한다.
Alpha가 커지면 트리의 terminal node가 조금만 많아도 CC값이 확 커져버리기 때문에 가지를 많이 쳐내서 단순한 모델을 만들게 된다.
반대로, 이 값이 작아진다면, terminal node가 많아도 CC값이 커지지 않기 때문에 조금 더 복잡한 모델이 만들어진다.
실제로 R에 rpart 라이브러리에서도 이 CP값으로 pruning을 진행한다.
앙상블이란?
앙상블 역시 과적합을 방지하는 방법 중 하나로, 대표적인 예가 Random Forest이다.
앙상블이란? 여러개의 Model을 조합하여 과적합을 방지하고, 예측의 정확도를 높히는 방법
Random Forest의 이름 자체를 살펴보면 좀 더 이해가 쉬울 것이다.
Forest는 숲이다. 나무들이 모이면 숲이된다. 즉, 형태가 조금씩 다른 Decision Tree 모델들이 모이면 Random Forest가 되는 것이다.
이 여러 모델들을 조합하는 방법에는 여러가지가 있는데, "투표"를 생각해보면 쉽다.
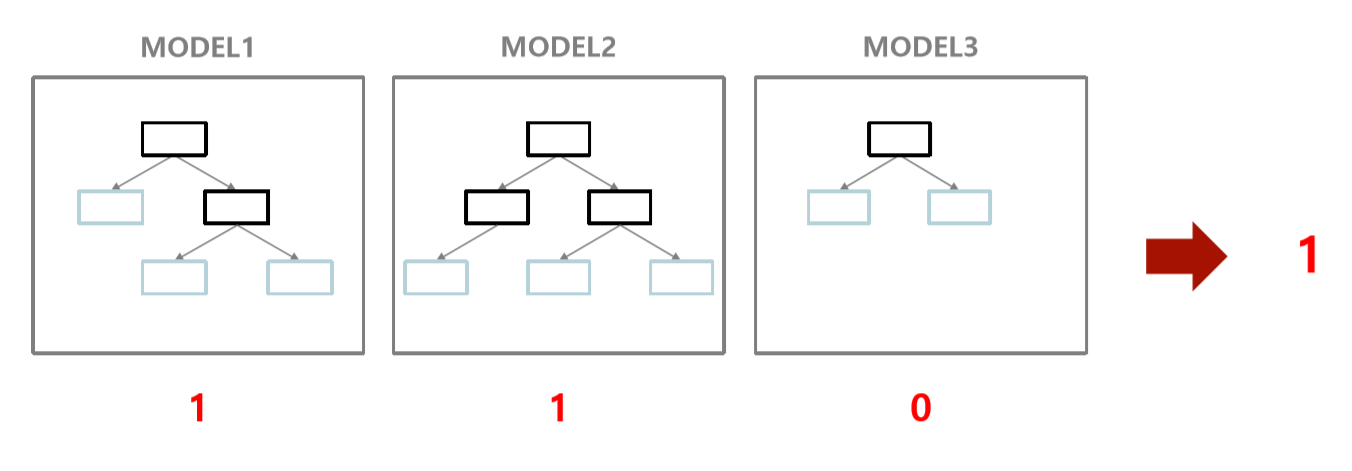
0과 1을 분류하는 문제에서 2개의 Model은 1이라 대답했고, 단 1개의 Model만이 0이라 대답했다. 다수결의 원칙에 따라 1이라 최종 결정하는 것이 앙상블의 핵심이다.
이는 어떤 질문을 전문가 1명이 아니라 "적당한 전문가" 다수에게 물어 본 후 다수결에 따라 결정하는 것과 같은 느낌이다.
참고로 Random Forest는 Decision Tree라는 같은 알고리즘으로 만들어진 모델 여러개로 조합했지만, 앙상블이 꼭 같은 알고리즘으로 만들어진 모델들로 조합할 필요는 없다. Decision Tree, DNN, Logistic .... 등 여러 다른 알고리즘으로 모델을 만들고, 이들을 조합하는 것 또한 앙상블이다.
지금까지 Decision Tree의 이론에 대해 알아보았다. 다음에는 실제 R에서 어떻게 사용할 수 있는지 실습코드를 소개하겠다.
'AI > Decision Tree Based Learning' 카테고리의 다른 글
| 의사결정나무(Decision Tree) :: 독립변수가 연속형 일 때 (2) | 2020.04.21 |
|---|---|
| 의사결정나무(Decision Tree) :: CART 알고리즘, 지니계수(Gini Index)란? (2) | 2020.04.21 |
| Decision Tree란? :: ID3 알고리즘, 엔트로피란? (2) | 2020.04.21 |