DALEX :: Variable Importance Measures in R
Deep Learning 모델을 Black Box 라 부르곤 한다. 설명이 가능한 Linear Regression과 같은 모델과 달리 layer가 많고 weight가 많아 모델에 대한 설명이 어렵기 때문이다.
이런 Black Box 모델들을 설명하고자 하는 needs가 꾸준히 있어왔고, 이를 XAI 혹은 eXplainable AI라 부른다.
R과 Python에서 이런 XAI가 가능한 패키지들을 몇가지 제공하고 있는데, 다음과 같다.

이 중 R에서 DALEX 패키지를 활용해서 Regression 문제와 Classification 문제를 나누어 변수 중요도 뽑는 방법을 소개하고자 한다.
Regression과 Classification을 나누는 이유는 각각이 요구하는 loss_function이 다르고, 그에 따라 prediction 결과도 달리 뽑아야 하기 때문이다.
(Regression 문제는 여기에 아주 잘 설명되어있으나, Classification에서는 loss_function에 따라 똑같이 따라하면 에러가 발생하여 이를 해결한 방법을 공유하기 위해 이 포스팅을 작성한다.)
아래는 DALEX에서 제공하는 loss function이다.
1. Regression
먼저 Regression 문제에서 변수 중요도를 계산하는 방법을 알아보겠다.
데이터와 모델은 DALEX 에서 제공하는 apartment 데이터와 rf모델을 사용한다.
apartments_test 데이터는 총 9000개의 row와 6개의 col을 가지고 있으며,
건축 년도, 층, 방의 개수 등으로 가격을 예측하는 문제이다.
먼저, 라이브러리를 선언하고, 모델을 다운받는다.
library("DALEX")
library("randomForest")
apartments_rf <- archivist::aread("pbiecek/models/fe7a5")
모델은 archivist 패키지에서 제공한다.
이미 누군가 apartment 데이터에 대해 random forest모델을 만들어 놓았다.
위에서 선언한 randomForest 패키지를 사용해 만들었다.
모델링에 사용한 apartments 데이터는 apartments_test와 같은 형태의 1000개 row로 이루어진 데이터셋이다. (test set과 겹치지 않는 train set이라 생각하면 된다.)
참고로 모델 성능은 다음과 같다.(test set에 predict한 결과이다.)
이제 모델을 설명하는 explain 객체를 만든다.
explainer_rf <- DALEX::explain(model = apartments_rf,
data = apartments_test[,-1],
y = apartments_test$m2.price,
label = "Random Forest")
미리 만들어 둔 모델을 넣어주고, Y값을 뺀 데이터를 넣어준다. y에는 target값을 넣어준다.
y에 넣어준 apartments_test$m2.price는 numeric형 타입이다.(나중에 classification은 loss_function에 따라 factor형을 넣어주어야 할 때도, numeric 형을 넣어 주어야 할 때도 있다.)

마지막으로 label은 안넣어주어도 된다.
나중에 여러개 모델을 비교하면서 그래프 그릴 때 label을 graph title로 그려주기 위함이다.
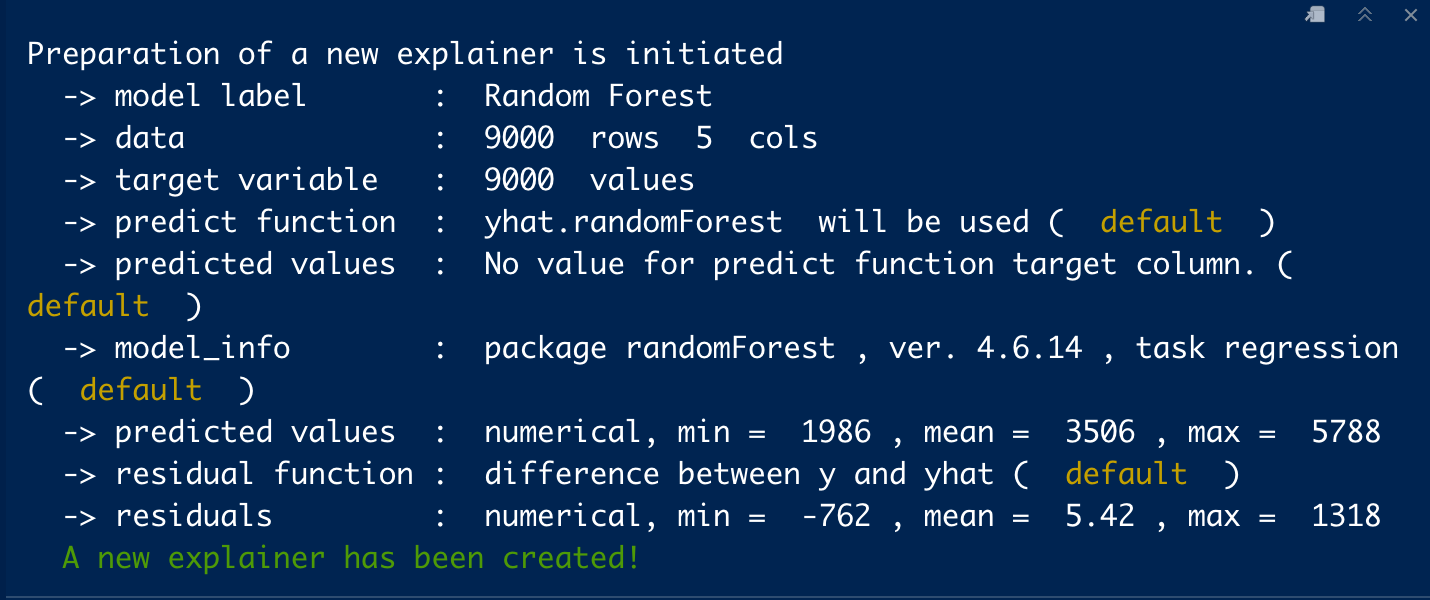
위 코드를 실행하면 다음과 같은 메세지가 뜬다.
전달한 파라미터들에 대한 간략한 설명들이다. 마지막에 성공적으로 생성했다는 메세지도 뜬다.
이제 model_parts() 로 변수 중요도를 계산한다.
set.seed(1980)
vip <- model_parts(explainer = explainer_rf,
loss_function = loss_root_mean_square,
B = 1)
explainer에 위에서 생성한 explainer_rf를 넣어주고, loss_function에 loss_root_mean_square를 넣어준다.
B는 변수 중요도 계산을 위해 내부에서 B번 반복해 예측한다는 뜻이며, 이는 아래서 더 자세히 설명하겠다.
seed에 따라서 변수 중요도가 달리 나올 수 있는데, 이 역시 아래 설명하겠다.
* loss_function
DALEX에서 제공하는 loss_function은 다음과 같은데,
loss_cross_entropy는 multi classification문제에서 사용하고,
loss_sum_of_squares와 loss_root_mean_sqare는 Regression 문제에서 사용한다.
loss_accuracy와 loss_one_minus_auc는 classification 문제에서 사용한다.

결과는 다음과 같다.
plot(vip)
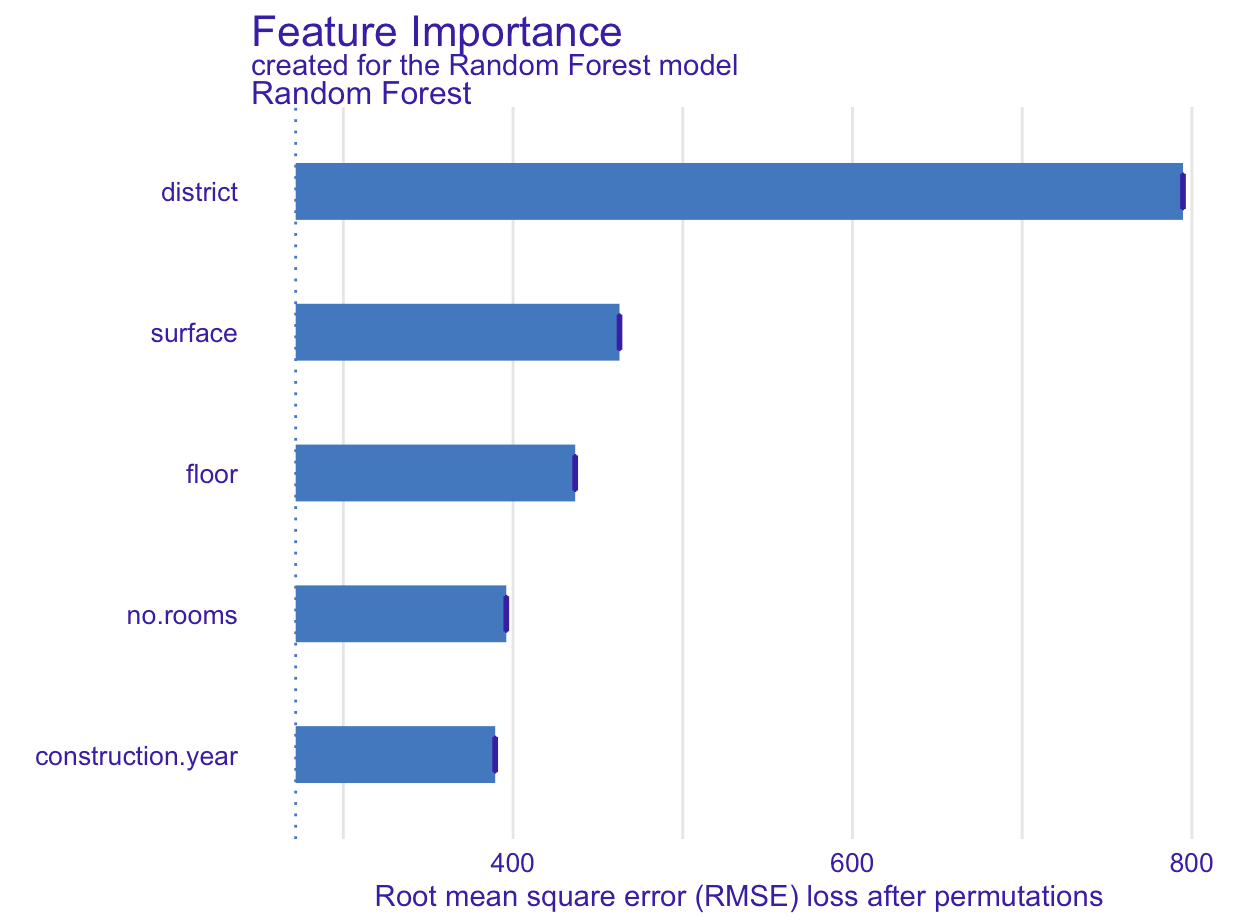
bar의 길이가 길수록 주요 변수라 해석하면 된다.
model_parts() 가 변수 중요도를 계산하는 로직은 구현된 코드를 보면 쉽게 알 수 있는데, 아래 이미지처럼 ingredients패키지의 feature_importance() function을 그대로 쓰고있다.

ingredients의 feature_importance()를 구현한 코드를 보기 전에 위에서 생성한 variable importance(vip) 결과를 보면 다음과 같다.
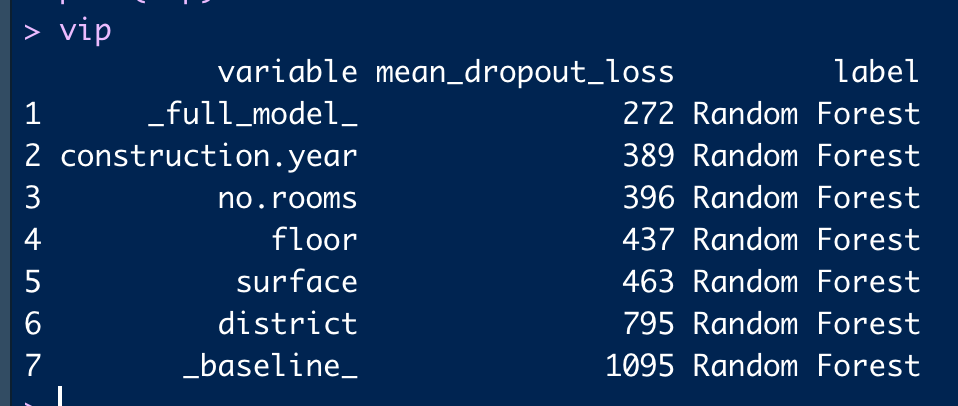
variable을 보면 모델에 사용된 변수들과 _full_model_, _baseline_에 대한 loss값 평균이 계산되어 있다.
(loss는 위에서 파라미터로 전달해준 rmse로 계산되었다.)
_full_model_은 전체 데이터셋을 그대로 넣고 prediction한 결과(loss)이고,
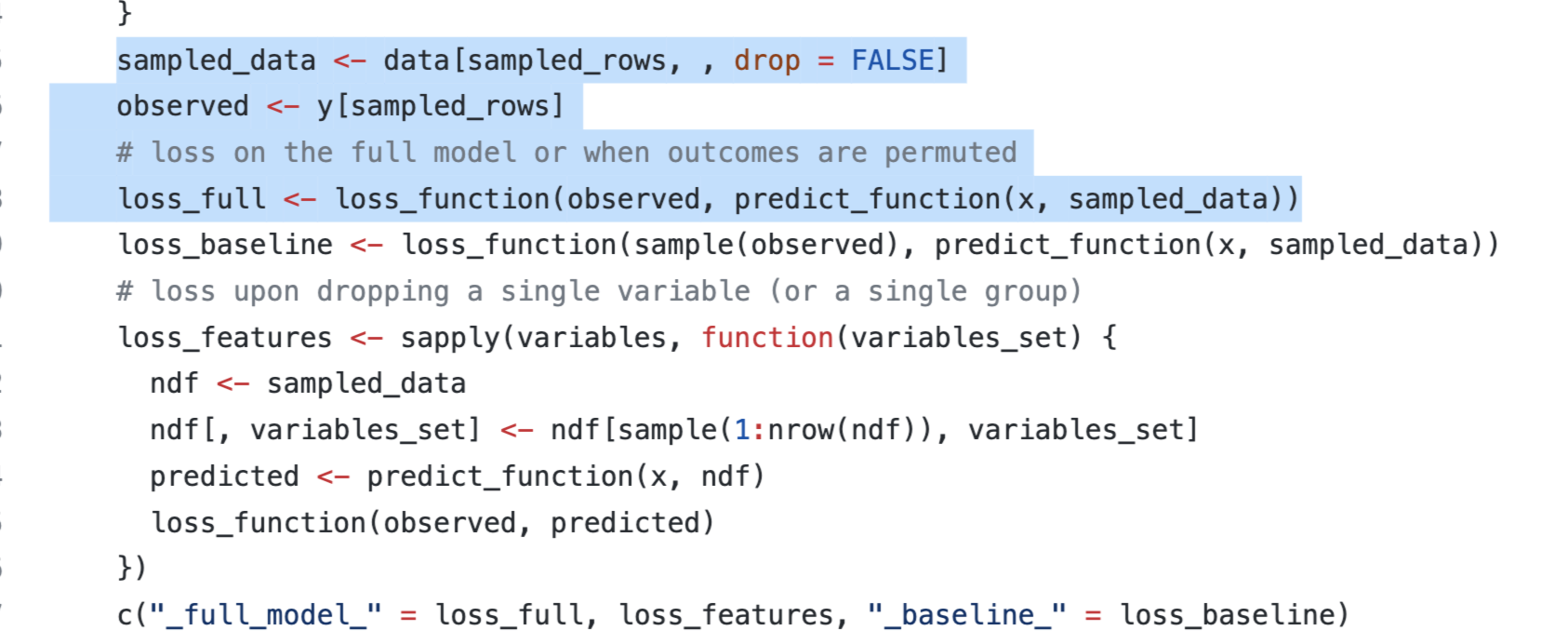
_baseline_은 X변수들과 Y값 모두 ramdom하게 순서를 섞은다음 prediction 한 결과이다.

그 외에 다른 변수들은
딱 그 해당 변수만 순서를 random하게 섞은 후 prediction한 결과이다.
즉, 중요한 변수라면 이 값을 random하게 섞었으니, 그 역할을 제대로 하지 못해 성능이 많이 떨어질 것이다.
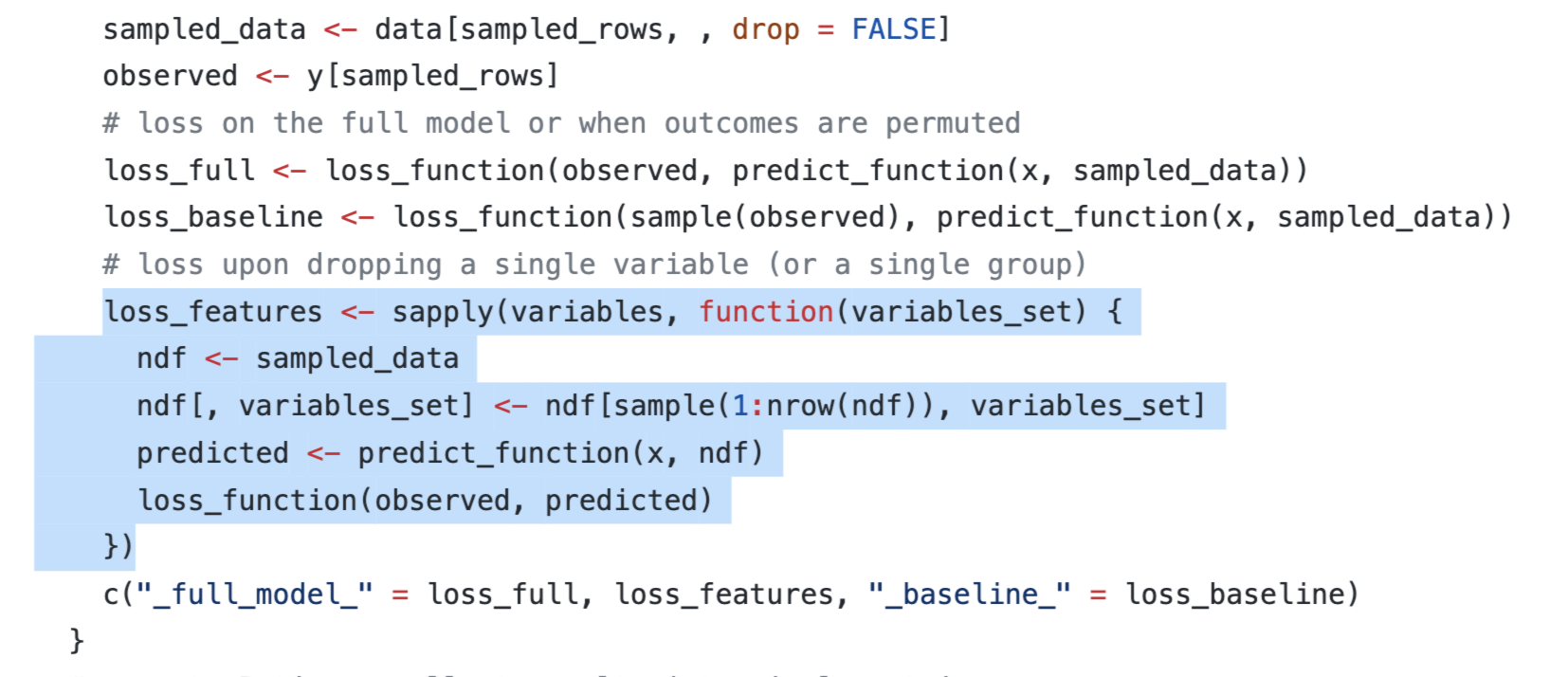
이를 총 B번 반복하여 평균낸 것이 위 vip table의 mean_dropout_loss 인 것이다.
나는 B를 따로 입력해 주지 않았고, default 값은 10이다. 즉, 위 과정을 10번 반복해, 계산된 loss를 평균낸다.

prediction할 때 random하게 순서를 섞는 이 random성 때문에 seed에 따라 결과가 조금씩 차이가 있을 수 있다.
이 때는 B의 값을 크게하면 좀 더 안정된 값을 얻을 수 있을 것이다.
이제 다시 돌아가서, 위의 결과를 다시 보면 district의 RMSE loss after permutations가 가장 높은 것을 볼 수 있다.
즉, 다른 변수에 비해 district 변수만 random하게 섞은 후 prediction 했을 때 loss가 가장 많이 증가한다는 뜻이다.
즉, district 변수가 가장 중요한 변수라 해석할 수 있고, bar의 길이가 길 수록 중요한 변수라고 해석할 수 있다.
외에 다른 loss들도 그 의미를 잘 파악하여 해석해야하는데, 대게 bar의 길이가 길수록 중요한 변수라 해석하면 된다.
Regression 문제에서 DALEX로 변수 중요도 계산하는 방법과 그 원리에 대해 알아보았다.
Claasification 문제에 대한 방법은 다음 포스팅에서 알아보겠다.
'AI > 잡지식' 카테고리의 다른 글
| AI(Artificial Intelligence) VS ML(Machine Learning) VS DL(Deep Learning) (1) | 2024.09.02 |
|---|---|
| [R] XIA(eXplainable AI) 패키지 중 DALEX로 변수 중요도 뽑기(classification) (2) | 2021.11.15 |
| 넬슨 법칙이란? What is the Nelson Rules? (0) | 2020.02.04 |
| KL divergence(Kullback–Leibler) (2) | 2018.09.21 |
| curse of dimensionality - 차원의 저주 (2) | 2018.09.20 |