이전 포스팅에서 Crawling이 무엇인지와 BeautifulSoup과 Selenium의 차이점,
웹페이지가 어떻게 구성되어있는지, HTML Tag란 무엇인지, BeautifulSoup으로 Tag를 어떻게 찾는 지 등에 대해 알아보았다.
2023.02.21 - [Python/Crawling] - Crawling in Python(request, BeautifulSoup, Selenium) (1)
Crawling in Python(request, BeautifulSoup, Selenium)
Python에서 Beautiful Soup과 Selenium으로 Crawling하는 방법 먼저 Crawling이란? 컴퓨터 소프트웨어 기술로 웹 사이트들에서 원하는 정보를 추출하는 것이다. 웹사이트도 코드로 짜여져있기때문에 어느정
leedakyeong.tistory.com
이번에는 실제 웹 페이지를 크롤링하는 실습을 해보고자 한다.
실습할 웹 페이지는 https://library.gabia.com/ 이다.

웹 페이지를 먼저 살펴보면
모두보기, 재택근무, 주52시간 등 키워드로 이루어진 메뉴가있고 각 메뉴마다 해당하는 포스팅들이 있다.
포스팅에 마우스를 올리면 아래와 같이 링크가 뜨고, 링크를 누르면 해당 포스팅을 볼 수 있다.

링크 클릭 시 위에 url도 바뀌는 것을 볼 수 있다.
해당 페이지에서 포스팅 제목, 포스팅 link 등을 추출하려면 먼저 페이지 소스를 받아오고, 그 소스를 BeautifulSoup으로 파싱하기 위해 BeautifulSoup 객체로 변환해주어야한다.
페이지 소스를 받아올 때는 requests 라이브러리를 사용한다.

requests.get() 안에 페이지 소스를 요청할 url을 입력한다.
결과는 상태코드도 같이 반환하는데, 200은 요청 성공이라는 뜻이다.
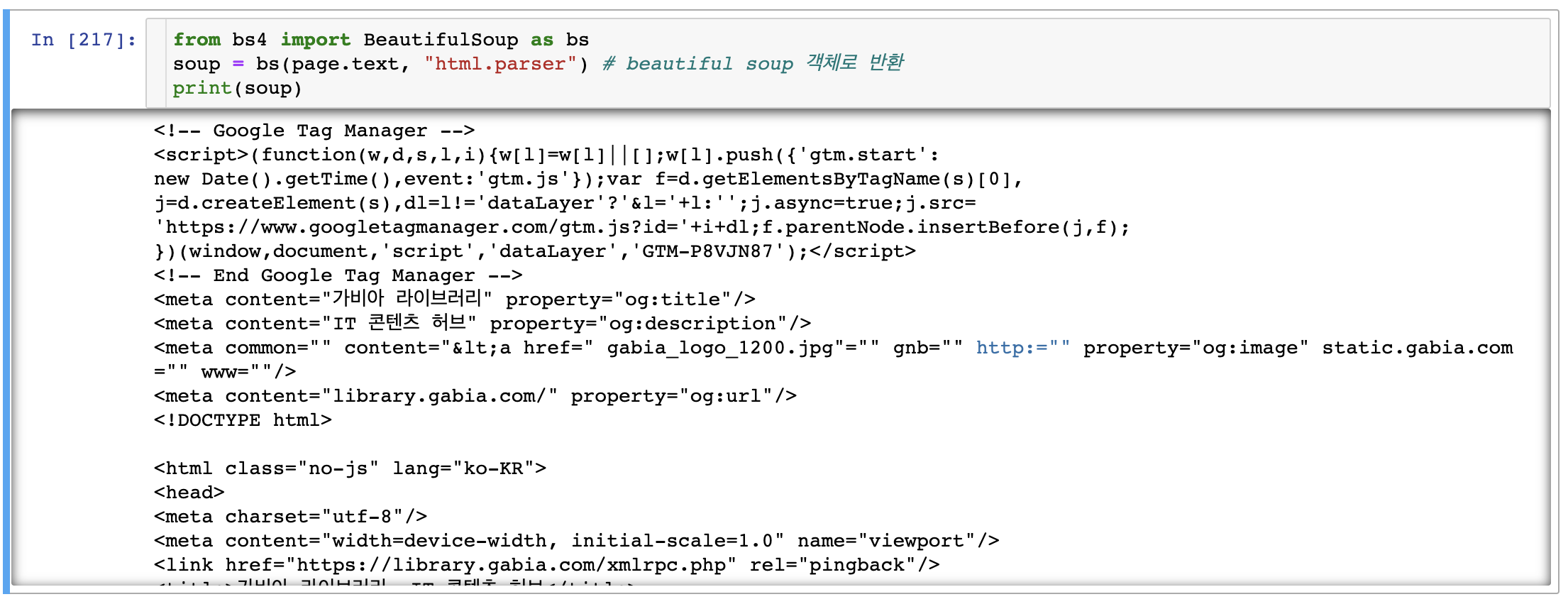
받아온 결과를 찍어보면 다음과 같다.

content와 text로 받아 온 소스를 확인 할 수 있는데, content는 페이지 소스를 byte 형태 그대로 반환하고, text는 byte 형태를 자동으로 decode해서 반환한다. 즉, text가 인코딩 문제를 자동으로 해결해주므로 text로 보는 것을 추천한다.
위 결과는 실습 중인 페이지에서 아무곳에서나 우클릭 -> 검사(혹은 페이지 소스보기)를 눌렀을 때 결과와 동일하다.


이제 불러온 소스를 BeautifulSoup 객체로 반환한다.
이제 Beautiful Soup으로 소스를 파싱할 준비가 끝났다.
먼저, 모두 보기, 재택근무, 주52시간 과 같은 메뉴들을 추출해 보겠다.
"모두 보기" 메뉴 우클릭 -> 검사 누르면 딱 해당하는 부분의 소스가 하이라이트되어 오른쪽에 나타난다.

<span>모두 보기</span> 으로 되어있다.
"재택근무" 메뉴도 마찬가지로 우클릭 -> 검사 눌러본다.

마찬가지로 <span>재택근무</span> 으로 되어있다.
그럼 이전 포스팅에서 배웠던 대로 select()로 "span" tag를 검색해 보겠다.
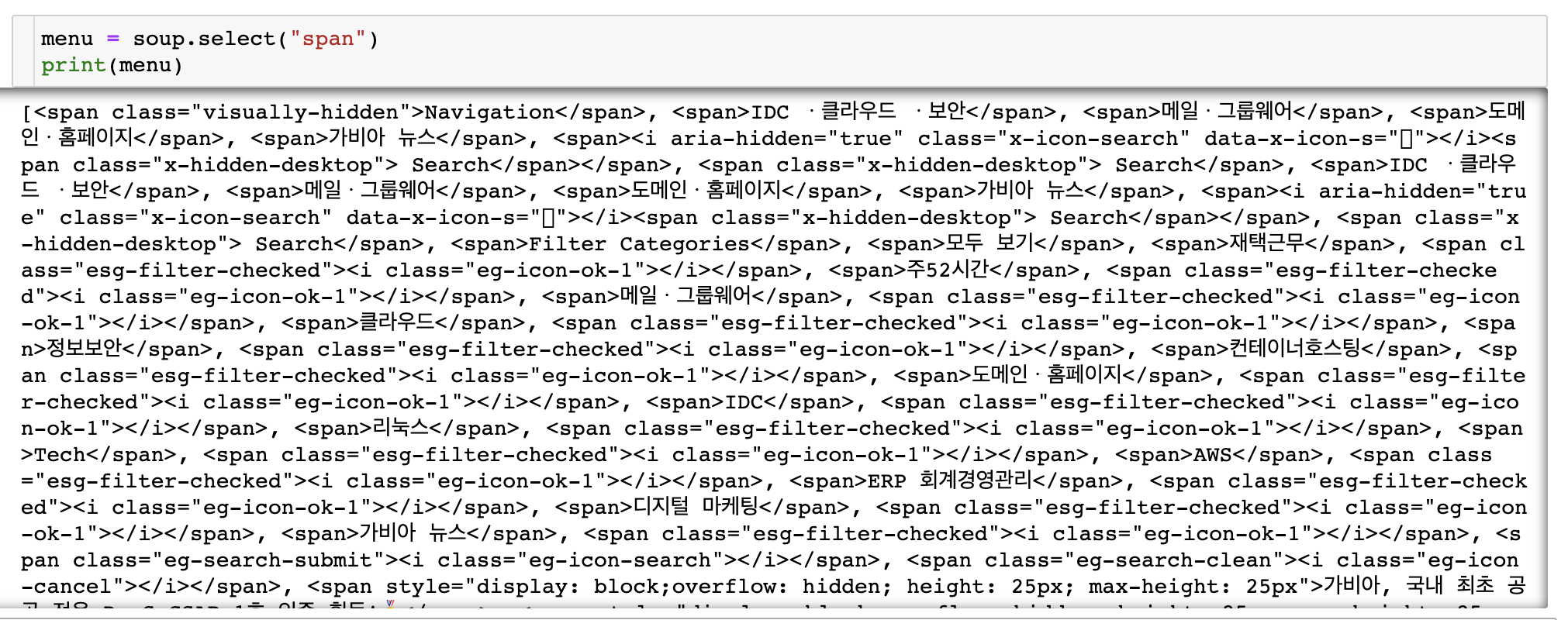
"span"이라는 tag가 워낙 많이 쓰이는 테그이다보니 원하는 정보들 뿐 아니라 너무나 많은 tag들이 검색된 것을 볼 수 있다.
다시 돌아가, span 바로 위에 테그를 살펴본다.
"모두 보기" span tag 바로 위에 <div class="esg-filterbutton ~~"> tag가 보인다.
마찬가지로 "재택근무" span tag 바로 위에도 <div class="esg-filterbutton ~~"> 가 보인다.
그럼 이번엔 span이 아니라 div tag의 class = "esg-filterbutton"으로 검색해보자.

15개 메뉴가 잘 검색되었음을 확인할 수 있다.
이처럼 웹 페이지의 소스들은 어느정도 정형화는 되어있지만 정답은 없다. 애초에 라이브러리 이름에 Beautiful이 들어가는 이유도 너무나도 더러운 Tag들을 Beautiful하게 만들어준다는 의미가 내포되어있다.
따라서 코드를 짠 후에는 꼭 그 결과를 확인해 주어야 한다.(첫 번째 결과 뿐 아니라 전체 결과를 모두 확인하는 습관을 들이는 것을 추천한다.)
* 참고로 <tag>[요기 내용]</tag> 에서 "요기 내용"은 .text로 뽑아올 수 있다.(검색 방법 및 tag에 대한 내용은 이전 포스팅 참고)
이번에는 포스터 제목들을 추출 해 보겠다.
마찬가지로 포스팅 제목에 마우스를 가져다대고 우클릭 -> 검사를 클릭한다.
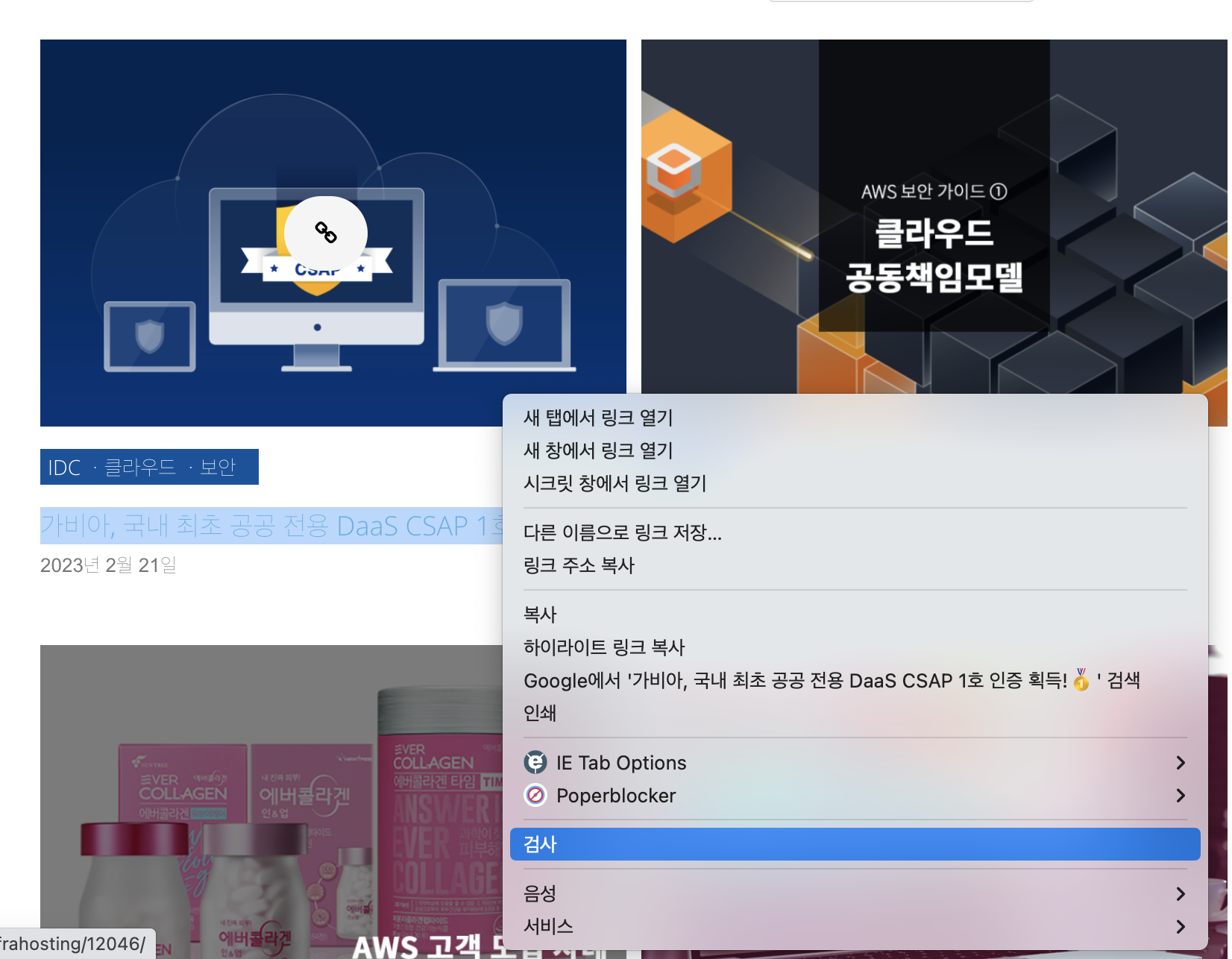

해당하는 소스가 하이라이트되어 뜨는 것을 볼 수 있다.
해당 소스만 확대해서 보면 다음과 같다.

span tag 위에 <a class = "eg-grant-element-0 ~~"> tag를 확인할 수 있다.
이 tag로 BeautifulSoup에 검색해보겠다.
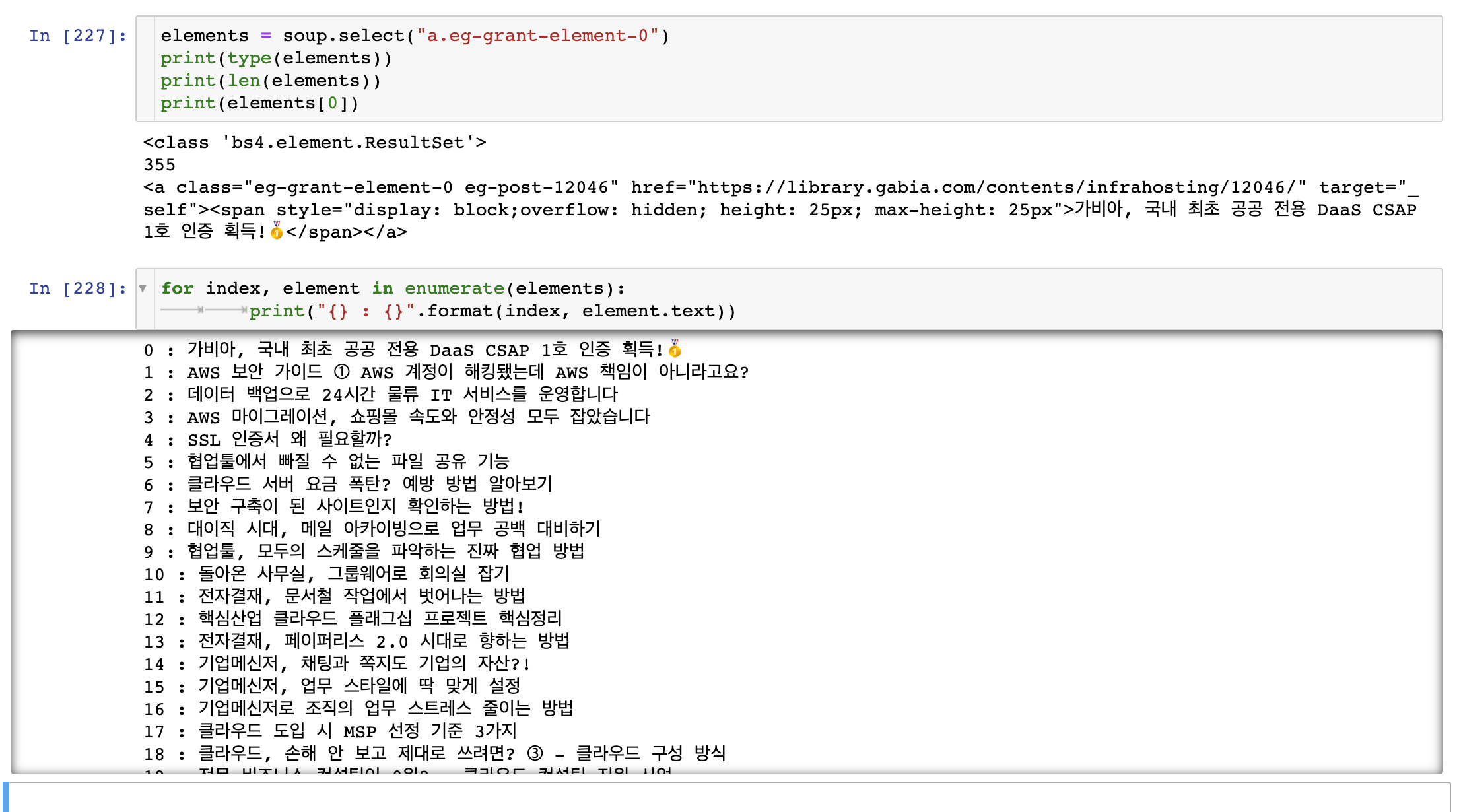
다른 포스터 제목들도 잘 추출해 낸 것을 확인할 수 있다.
이번에는 포스터 제목들과 각 포스터들의 연결 url 주소도 같이 추출해 보겠다.
위에서 이미 추출했던 element를 보면 다음과 같다.

href = "" 에 url이 들어있다.
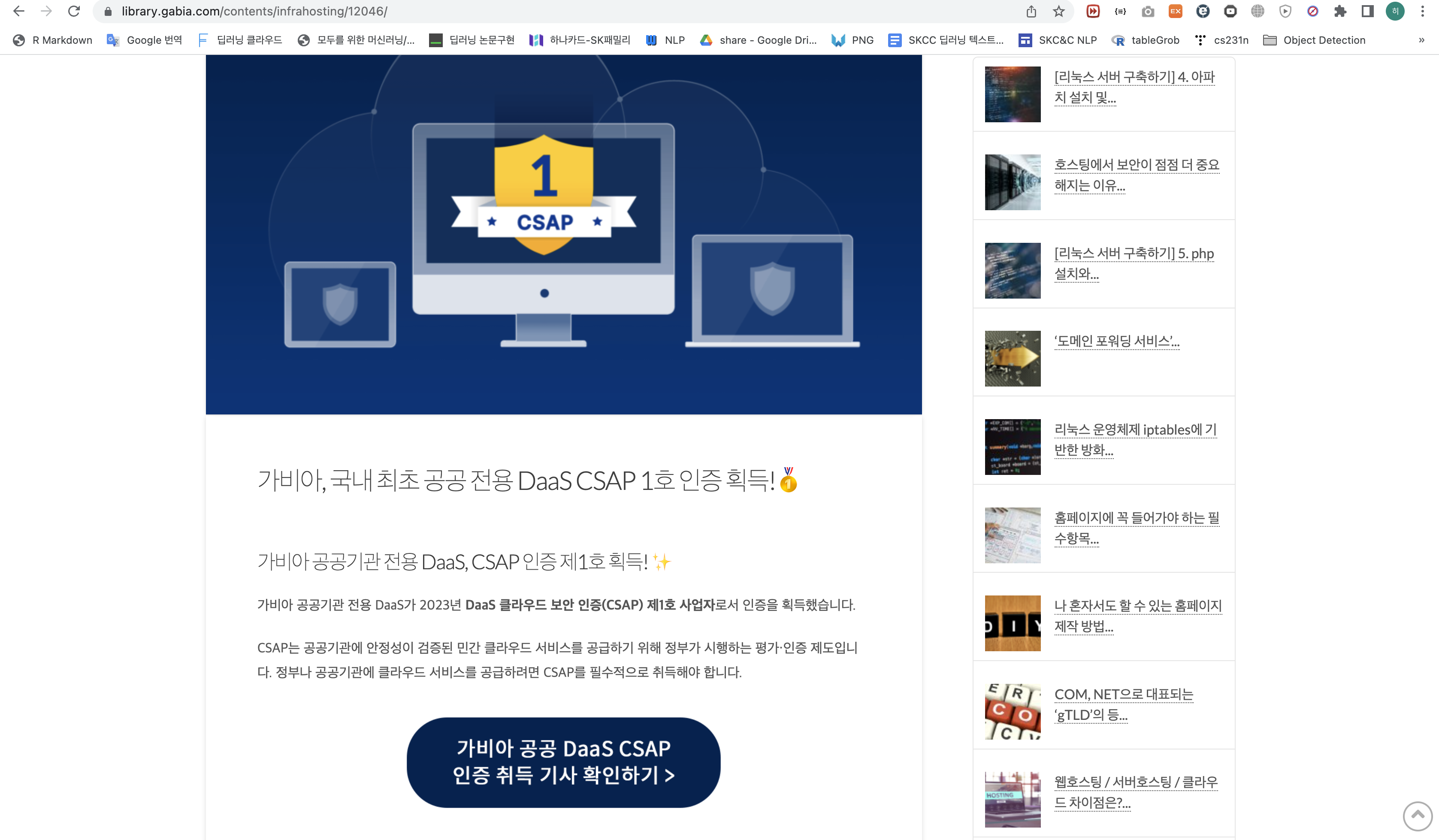
실제 해당 포스팅의 url임을 확인할 수 있다.
이는 element.attrs['href]로 뽑아 올 수 있다.

각 포스터별로 url 도 알았으니, 그 url 페이지의 소스를 다시 request 받아, 기사 내용도 크롤링 할 수 있다.

첫 번째 포스터에 대해 url을 받아오고, 해당 url을 다시 request해서 페이지 소스를 받아온 다음에 BeautifulSoup 객체로 변환했다.
그 결과는 다음과 같다.

\n 등 지저분하게 추출된 것을 볼 수 있다. ("\n" 은 줄바꿈을 의미한다.)
이를 좀 더 깔끔하게 추출하면 다음과 같다.
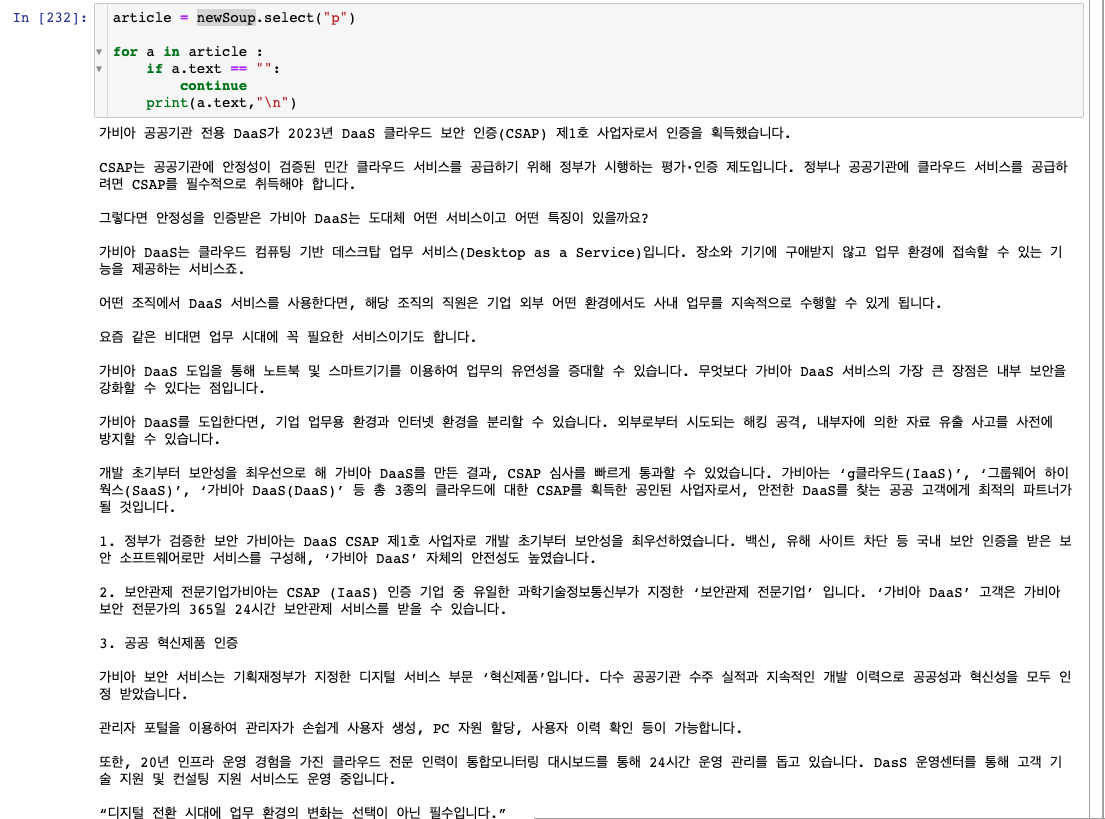
newSoup.text의 type이 str이므로 일반적인 string 객체 처리하듯이 정규표현식을 활용하여 처리해도되고,
위와 같이 "p" tag만 받아와서 처리해도된다.
위에서 언급했든 정답은 없으므로 각자의 상황에 맞게 적용하면 된다.
마지막으로 메뉴들 중 "재택근무"에 해당하는 포스터 제목만 추출해 보겠다.
재택근무 메뉴를 클릭하면 포스터들이 바뀐다.
하지만 위에 url은 바뀌지 않는다.
즉, 위에 포스터 기사를 크롤링 했듯이 바뀐 url을 다시 request 받아서 진행할 수가 없다.
이럴 때 selenium을 사용한다.
selenium은 이전 포스팅에서 설명했듯이 클릭, 스크롤, 검색 등의 웹 사이트 제어 기능을 한다.
selenium을 통해 "재택근무" 메뉴를 클릭한 다음 해당 포스터 제목들을 추출하면 된다.
이를 위해 필요한 라이브러리들은 불러온다.
|
1
2
|
from selenium import webdriver
from selenium.webdriver.common.by import By
|
cs |
그리고 크롬 창을 실행한 다음 url을 검색한다.
|
1
2
|
dr = webdriver.Chrome() # 크롬 드라이버 실행
dr.get("https://library.gabia.com/") # 크롬에서 해당 url이 열리는지 확인
|
cs |
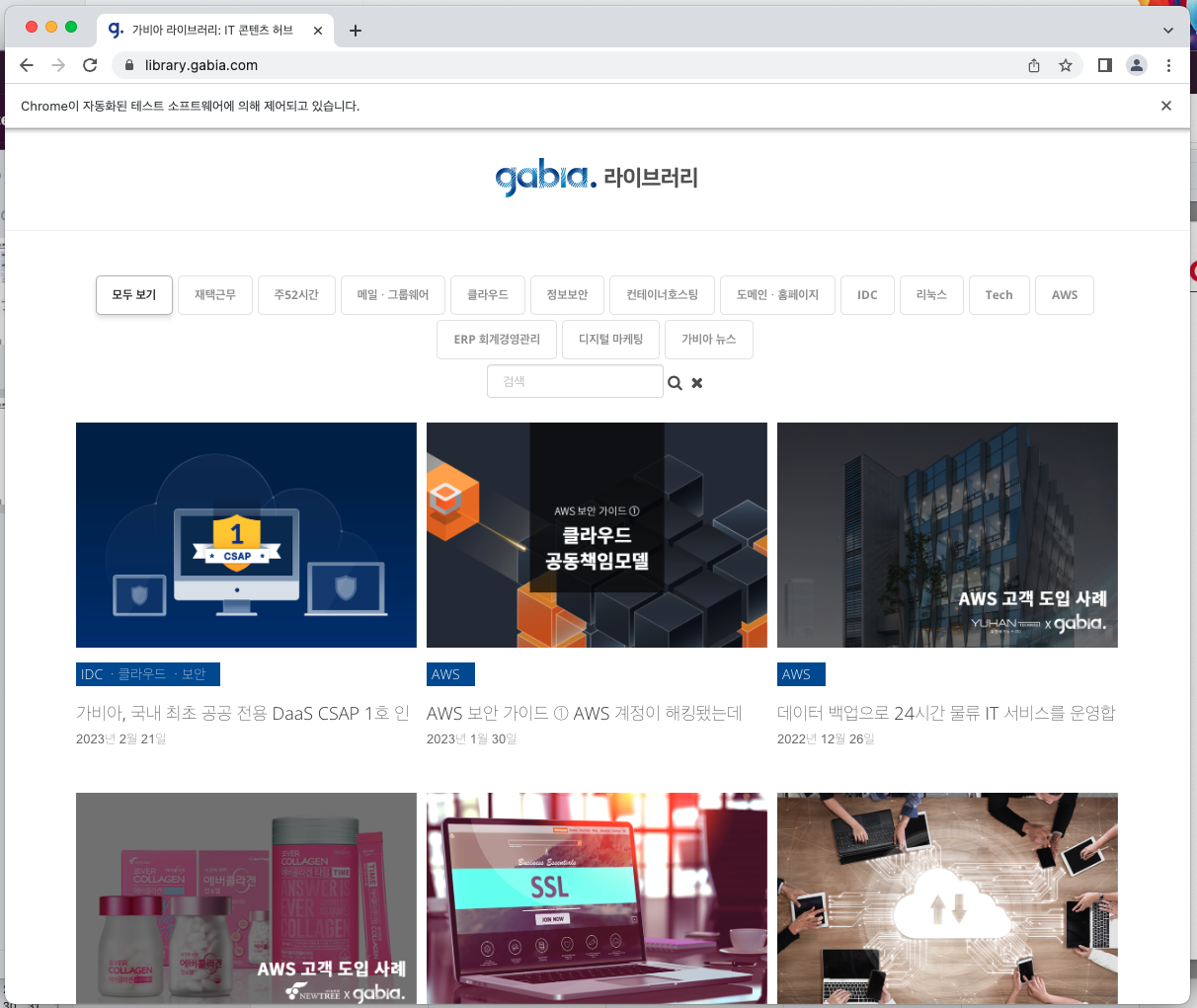
위 이미지와같이 크롬창에 검색한 유알엘이 잘 뜨는지 확인한다.
인터넷창 위에 "Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다." 라는 문구도 확인할 수 있다.
이제 메뉴 버튼을 찾아서 클릭한다.
메뉴 버튼은 위에서도 찾았으니 그대로 사용한다.
이 중 "재택근무" 버튼을 찾아 클릭한다.

셀레니움으로 켰던 크롬창에서 "재택근무" 버튼이 클릭된 것을 확인할 수 있다.
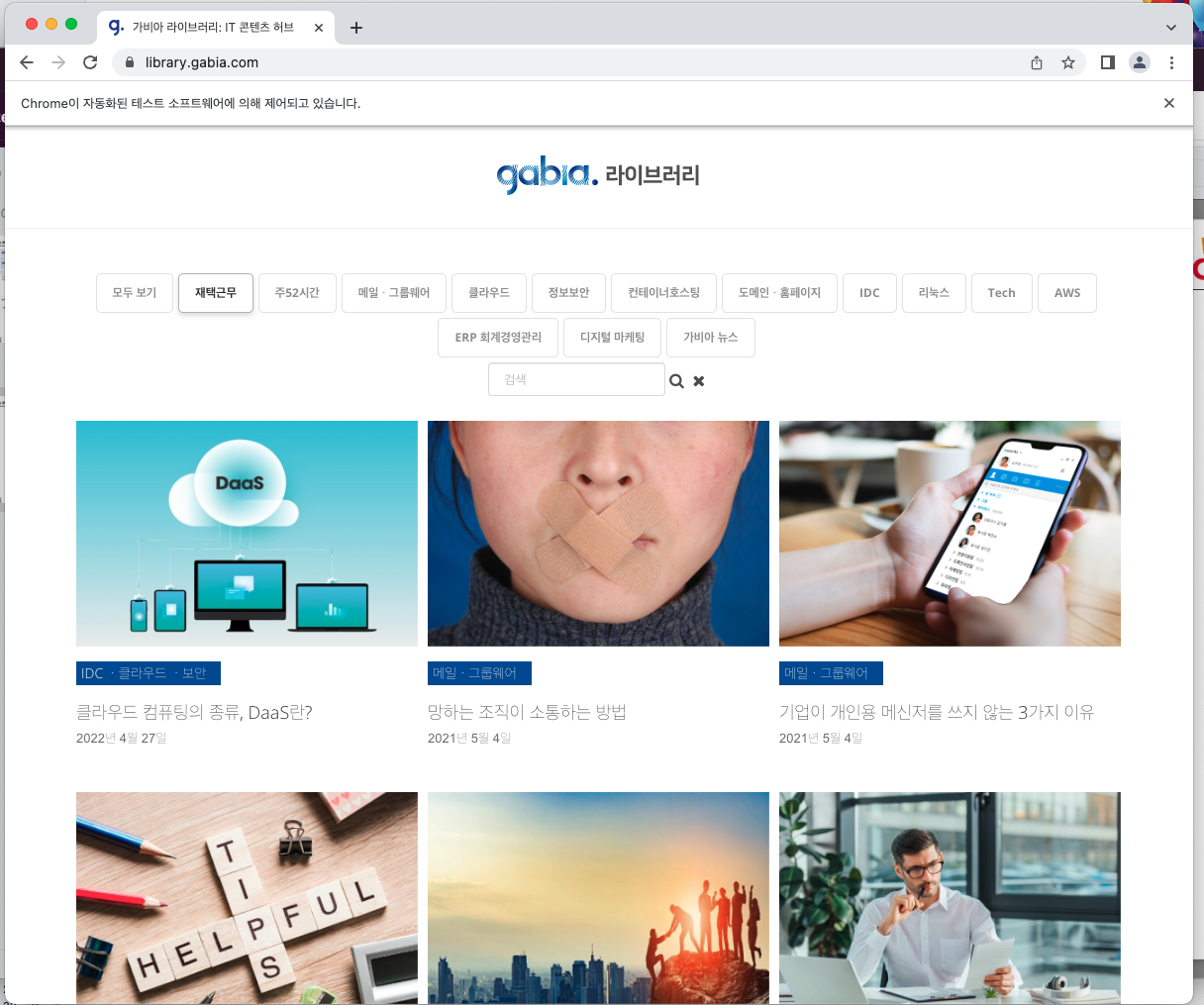
이제 이 페이지 소스를 request해서 다시 BeautifulSoup을 이용하여 포스터 제목을 추출하면 된다.


.page_source로 페이지 소스를 requrest하고 그 소스를 BeautifulSoup 객체로 변환했다.
이제 포스터 제목을 추출하기 위해 위에서 했던대로 a class = "eg-grant-element-0"로 Tag를 찾아보겠다.

"재택근무" 메뉴에 해당하는 포스터 뿐 아니라 "모두 보기" 메뉴에 해당하는 모든 포스터 제목들이 추출되었다.
즉, 기존처럼 a tag로는 "재택근무"에 해당하는 포스터 제목을 추출할 수 없다.
다시 페이지로 돌아가 우클릭 -> 검사로 "클라우드 컴퓨팅의 종류, DaaS란?" 포스터 제목과 "가비아, 국내 최초 공공 전용 DaaS CSAP 1호 인증 획득!" 포스터 제목에 어떤 차이가 있는지 확인한다.


첫 번째 이미지가 "재택근무" 메뉴에서 보이는 포스터의 소스이고, 아래 이미지가 "재택근무" 메뉴에서 보이지 않는 포스터의 소스이다.
기존처럼 a tag로 불러오면 "재택근무" 메뉴에서 보이지 않던 포스터 제목까지 불러와졌던 이유이다. 다른 포스터들도 숨겨져 있을 뿐 존재한다.
소스코드를 더 위로위로 올라가다보면 li tag에 style= visibility 부분에 차이가 있음을 확인할 수 있다.
메뉴 클릭 시 보이는 포스터는 style= visibility : inherit로 되어있고, 보이지 않는 포스터는 style= visibility : hidden 으로 되어있다.
따라서 li tag와 style에 visibility로 구분하여 추출해야 한다.

이처럼 크롤링에는 정답이 없고 HTML tag는 개발자에따라 매우 다르게 작성되어있음을 인지하고, 추출 후에는 모든 결과에 대해 잘 되었는지 꼭 확인해야 한다.
'Python > Crawling' 카테고리의 다른 글
| [Python - Crawling] API 활용하여 날씨 예보 데이터 호출하기(OpenWeatherMap) (0) | 2023.06.29 |
|---|---|
| [Python - Crawling] API 활용하여 과거 기상 관측 데이터 불러오기 (3) | 2023.03.28 |
| Crawling in Python(request, BeautifulSoup, Selenium) (1) (0) | 2023.02.21 |