Python에서 Beautiful Soup과 Selenium으로 Crawling하는 방법
먼저 Crawling이란?
컴퓨터 소프트웨어 기술로 웹 사이트들에서 원하는 정보를 추출하는 것이다.
웹사이트도 코드로 짜여져있기때문에 어느정도 정형화되어있다. 이러한 규칙들을 기반으로 원하는 정보만 추출하는 것이 바로 웹 크롤링이다.
뉴스 기사 웹페이지에서 기사 제목이나 기사 내용들을 수집한다던가, SNS에서 포스팅 내용, 좋아요 수 등을 수집하는 것 모두 크롤링이라 할 수 있다.
이를 Python으로 진행해 볼건데, 가장 대표적인 Library가 Beautiful Soup과 Selenium이다.
두 라이브러리로 본격 크롤링을 하기 전에 웹이 어떻게 구성되어있는지를 먼저 알아보겠다.
다음은 많이 보는 네이버 웹페이지이다.
아무곳이나 우클릭 -> 검사(혹은 페이지 소스보기)를 누르면 해당 웹페이지가 어떻게 짜여져 있는지 소스코드를 볼 수 있다.

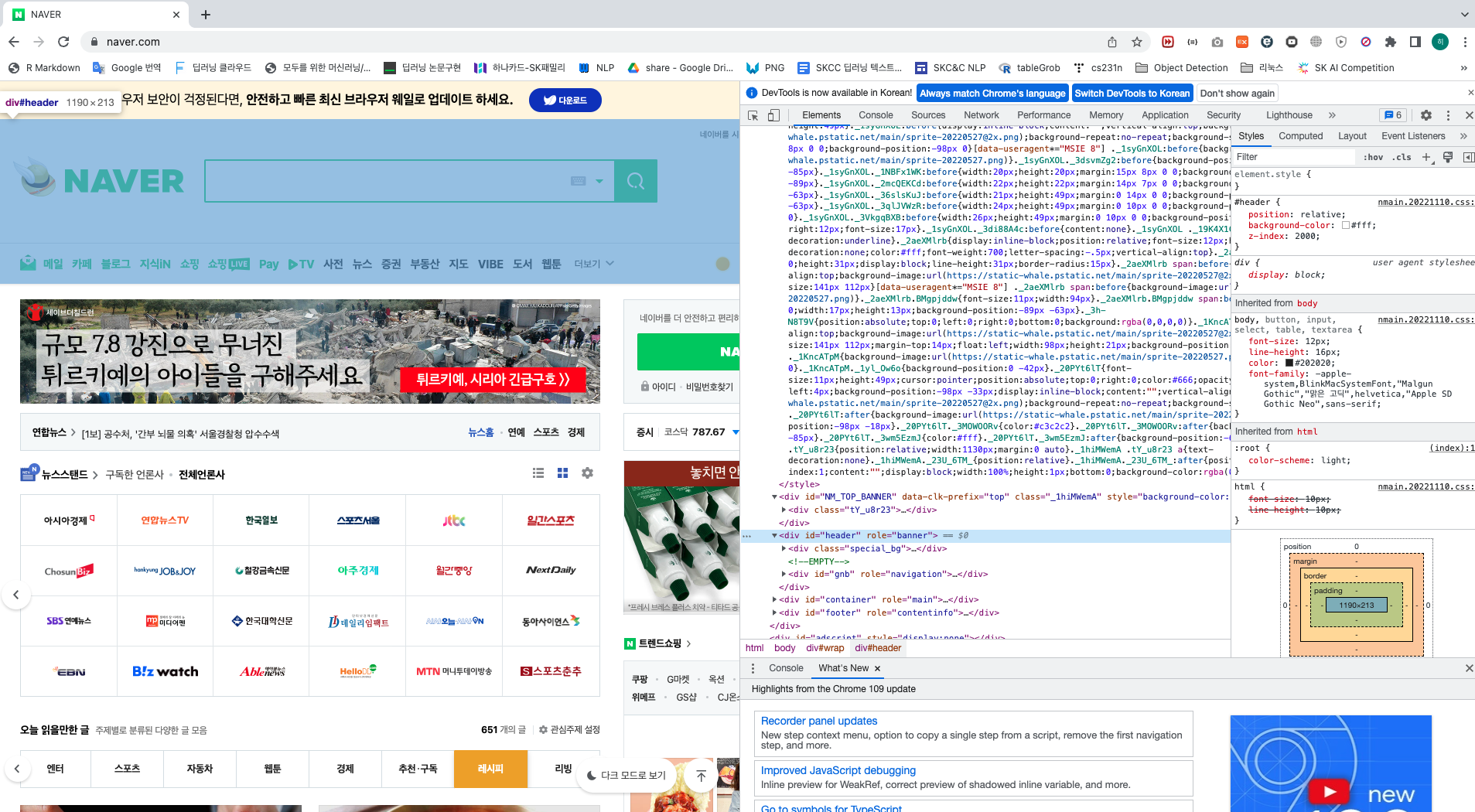
이렇게 웹 페이지는 HTML 형태로 짜여져 있으며, 우클릭 -> 검사 혹은 페이지 소스보기로 코드 소스를 확인할 수 있다.
다음과 같이 검사창에서 특정 코드에 마우스를 가져다대면 해당 코드가 웹 페이지의 어느부분을 구현한 건지 하이라이트된다.
이렇게 소스를 기반으로 웹페이지에서 원하는 정보를 얻어올 수 있다.
이 소스들은 Tag라는 것들로 이루어져있으며, 이 Tag들을 기반으로 원하는 정보를 뽑아오는 것이 바로 크롤링이다.
여기서 Tag란 웹 페이지에 대상이 되는 부분에 글씨 크기, 글자색, 글자 모양 등을 변경하거나 Link를 걸거나 이미지를 띄우는 등 어떤 표시를 해 주는 것이다.
Tag 예시는 다음과 같다.
<p>Hello</p>
기본적으로 <tag_name> ... </tag_name> 형태로 이루어져있다.
예로 네이버에서 "평당 3211만원에 집 팔려던 안양 재건축 조합원들의 근황" 이라는 기사 제목을 HTML tag로는 다음과 같이 나타내고 있다.
<strong class="title elss">평당 3211만원에 집 팔려던 안양 재건축 조합원들의 근황</strong>
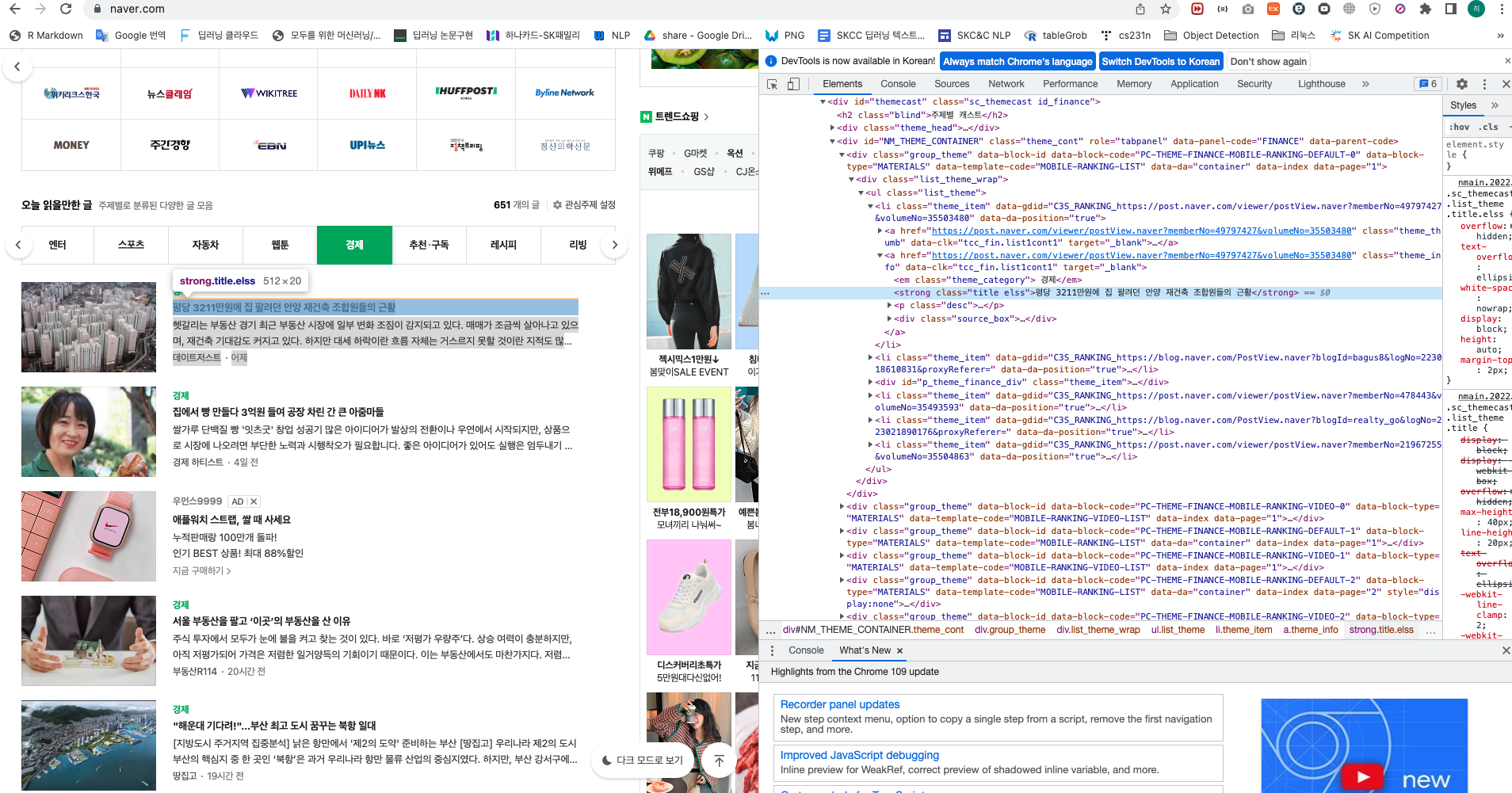
좀 더 자세히 보면 Tag는 <tag_name attribute = value> text </tag_name> 와 같은 형태로 이루어져있다.
tag_name의 예로는 p, span, div, strong 등이 있고, attribute의 예로는 id, class 등이 있다.
(참고로 p는 문단을 나타내는 tag, span는 inline tag를 나타낸다. 각각에 대한 의미가 무엇인지 알고있으면 더 좋으나, 몰라도 크롤링은 가능하므로 자세한 설명은 각자 찾아보길 바란다.)
Python에서 크롤링을 할 때 사용하는 대표적인 라이브러리는 BeautifulSoup과 selenium이다.
두 라이브러리의 차이점은 BeautifulSoup은 위에서 웹 페이지 소스에서 원하는 부분들만 파싱(Parsing)하는데 사용하는 라이브러리이고, Selenium은 웹 사이트를 자동으로 제어하는데 사용하는 라이브러리이다.
참고로 웹 페이지 소스를 불러오는건 request 라이브러리를 사용한다.
위 네이버 페이지를 예를 들면, BeautifulSoup은 웹 페이지 소스를 request 한 다음에, 뉴스스탠드에서 언론사에 어떤게 있는지 뽑아온다던지, 오늘 읽을만한 글에서는 어떤 메뉴들이 있는지 뽑아온다던지 하는데 사용한다.
반면 Selenium은 오늘 읽을 만한 글에서 엔터 메뉴를 "클릭" 한다던지, 페이지를 아래로 "스크롤"한다던지, 어떤 키워드를 "입력"하고 "엔터"를 친다던지 등 웹 사이트를 제어하는데 사용한다.
BeautifulSoup은 웹 페이지 소스에서 특정 Tag를 찾는 것이 목적이다. find() 객체와 select() 객체를 사용한다.
(실제 웹 페이지로 실습하는 부분은 아래서)
find()나 select_one() 객체는 가장 처음 발견한 tag만 return하고, find_all()이나 select() 객체는 해당하는 모든 tag를 return한다.
예로 다음과 같은 웹 페이지 소스 예시가 있다고 하자.

필요한 라이브러리를 불러오고, 위 소스를 BeautifulSoup 객체로 반환한다.
|
1
2
|
import requests # 페이지 소스 받아오기
from bs4 import BeautifulSoup as bs # 받아온 페이지 소스 parsing
|
cs |
"p" tag에 대한 정보를 뽑아내고 싶으면 다음과 같이 할 수 있다.
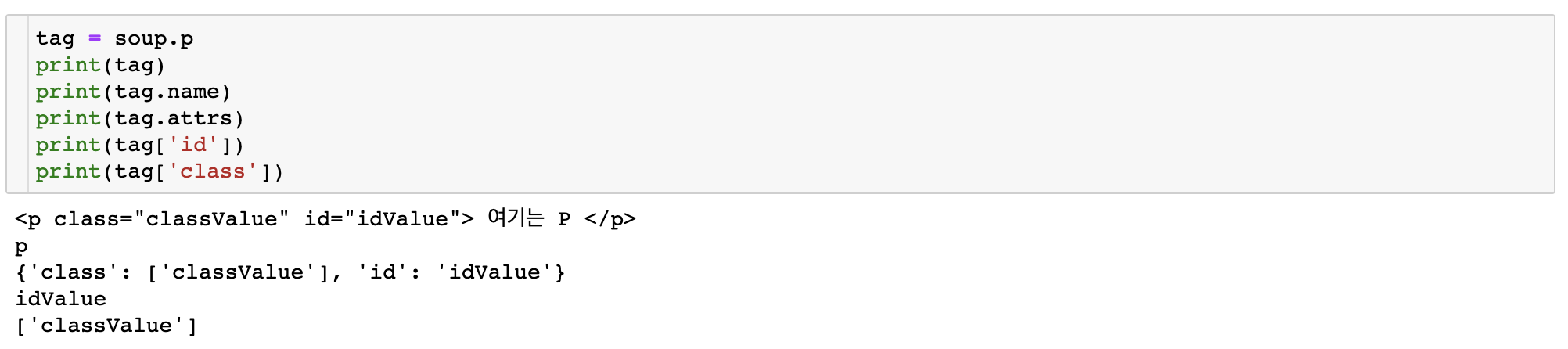
soup.p로 "p" tag에 대한 정보를 집어놓고,
tag.name으로는 tag name,
tag.attrs로는 attribute,
tag['id']로는 id attribute에 해당하는 value,
tag['class']로는 class attribute에 해당하는 value를 뽑아올 수 있다.
"div" tag에 대해서도 마찬가지이다.

이제 find() 에서 tag name으로 tag를 뽑아오는 방법은 다음과 같다.

혹은 attribute와 value로 뽑아오는 방법이다.

위 예시에서 find()와 find_all()의 차이도 확인할 수 있다.
다음은 select()로도 tag를 뽑아오는 방법이다.
tag name 기준으로 다음과 같이 찾을 수 있다.

attribute 중 class에 대해서는 다음과 같이 "."을 활용하며, id에 대해서는 "#"을 활용한다.

tag name과 class 또는 id로는 다음과 같이 할 수 있다.

find()와 select()가 tag를 특정하는 방식은 비슷하나, 특정 경로의 태그를 반환할 때 find는 반복적으로 코드를 작성해야하고, select는 직접 하위 경로를 지정할 수 있다.
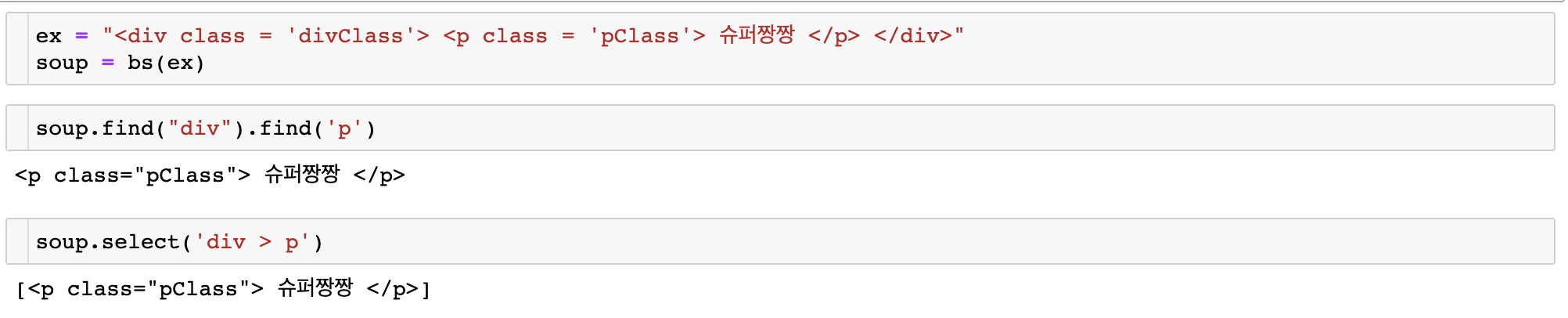
또한 select가 더 수행시간도 빠르고 메모리 소모량도 적다고 하니 find보다는 select를 추천한다.
본격적으로 실제 웹페이지를 크롤링하는 실습은 다음 포스팅에서 이어나가겠다.
2023.02.22 - [Python/Crawling] - Crawling in Python(request, BeautifulSoup, Selenium) (2)
'Python > Crawling' 카테고리의 다른 글
| [Python - Crawling] API 활용하여 날씨 예보 데이터 호출하기(OpenWeatherMap) (0) | 2023.06.29 |
|---|---|
| [Python - Crawling] API 활용하여 과거 기상 관측 데이터 불러오기 (3) | 2023.03.28 |
| Crawling in Python(request, BeautifulSoup, Selenium) (2) (0) | 2023.02.22 |