Data Scaling in R
데이터 scale 이란 전처리 과정 중 하나로, 각 컬럼의 분포를 맞춰주기 위해 필요한 과정이다.
scale 과정 없이 모델링을 한다고 했을 때 문제점은
예를 들어, X1의 범위는 0~1 이고, X2의 범위는 100000~10000000, Y값의 범위는 100000~10000000 이라하자.
사실 X1이 중요한 변수라 해도 그 값이 너무 작아 Y에 영향을 미치지 못한다고 판단할 수 있다.
외에도 계산 과정에서 수렴, 발산 등의 문제도 발생할 수 있다.
scale 방법에 여러가지가 있는데, 가장 많이 사용하는 두 가지 방법을 소개하고자 한다.
1. 표준화(Standardization)
각 observation이 평균으로 부터 어느정도 떨어져 있는지 나타낼 때 사용된다.
값의 단위가 다른 변수들이 있을 때, 그 차이를 제거해주는 효과가 있다.
평균을 0, 분산을 1로 맞추어준다.
$$ x_{scale} = \frac{x-\mu}{\sigma} $$
이를 R에서는 다음과 같이 하면된다.
(iris 데이터 사용)
|
1
2
3
|
# standardization
scale_model <- caret::preProcess(iris[,-5], method = c("center","scale"))
iris_stand <- predict(scale_model, iris)
|
cs |
caret package에 preProcess function을 사용했으며,
Standardization방식으로 scaling하려면 method에 "center"와 "scale"을 써주면 된다.
(iris 데이터의 5번째 컬럼은 label이므로 빼고 입력)
표준화 방식으로 스케일된 데이터의 평균과 표준편차는 다음과 같다.
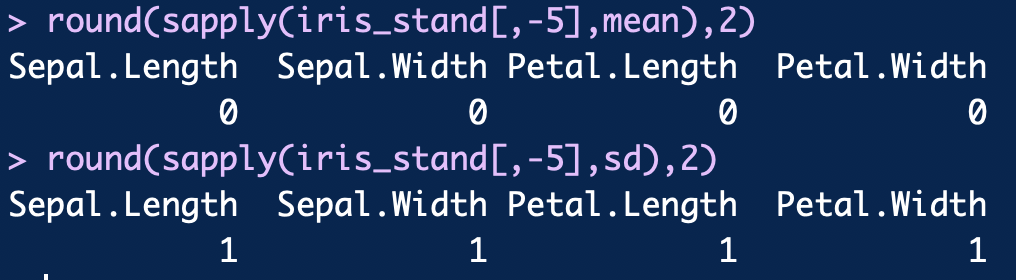
참고로 caret 패키지의 preProcess를 쓰지 않고 그냥 scale 함수를 쓰거나, 직접 구현하는 방법도 있다.
|
1
2
3
4
5
6
7
|
## scale
iris_stand2 <- iris
iris_stand2[,-5] <- scale(iris[,-5])
## 직접 구현
iris_stand3 <- iris
iris_stand3[,-5] <- sapply(iris[,-5], function(x) {(x-mean(x))/sd(x)})
|
cs |
2. 정규화(Normalization)
데이터의 범위를 0~1로 변환하여 분포를 조정하는 방법이다.
$$ x_{scale} = \frac{x-x_{min}}{x_{max}-x_{min}} $$
이는 R에서 다음과 같이 할 수 있다.
|
1
2
3
|
# normalization
scale_model <- caret::preProcess(iris[,-5], method = "range")
iris_range <- predict(scale_model, iris)
|
cs |
정규화 방식으로 스케일링 할 때는 method에 "range"를 파라미터로 넣어준다.
정규화 방식으로 스케일링된 데이터의 범위는 다음과 같다.
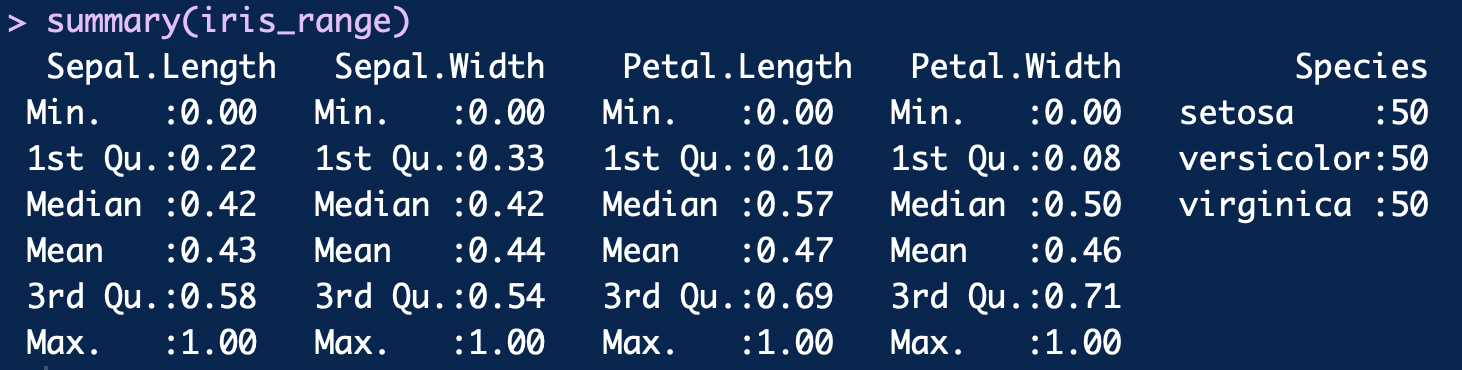
label인 마지막 컬럼을 제외하고 모두 min=0, max=1임을 볼 수 있다.
역시 직접 구현하는 방법은 다음과 같다.
|
1
2
3
|
## 직접 구현
iris_range2 <- iris
iris_range2[,-5] <- sapply(iris[,-5], function(x) {(x-min(x))/(max(x)-min(x))})
|
cs |
'R' 카테고리의 다른 글
| [R] How to expand rows by date range using start and end date? (0) | 2021.03.26 |
|---|---|
| [R] caret 패키지로 modeling & model tuning (iris classification :: knn algorithm) (0) | 2020.09.16 |
| 윈도우 작업 스케줄러에 R script 등록하기 (2) | 2020.03.05 |
| [R] Nelson Rules in R (5) | 2020.02.04 |
| [R] R에서 eval() 함수로 표현식 실행하기 (eval in R) (0) | 2019.09.18 |